이 포스트에서는 scale up, scale out, 트래픽과 함께 기초적인 로드 밸런서 지식을 다룬다. 끝에서는 로드 밸런스와 리버스 프록시를 비교한다.
Index
- Intro: 터져버린 서버에 우아하게 대처하기
- 로드밸런서
- (plus) 리버스 프록시
Intro: 터져버린 서버에 우아하게 대처하기
몇 년 전에 Spring Boot로 어드민 모니터링 사이트를 개발하는데 사용자 활동 데이터를 봐야하는 API 개발에 미숙하여 페이지에 페이지네이션을 넣지 않았다. 활동 데이터라 수시로 많은 데이터가 생성이 되는데 페이지네이션까지 넣지 않다보니 쿼리를 실행하는 것에 굉장히 오랜 시간이 걸렸다. 쿼리가 느린 것은 두 번째 문제이고 Heap이 터지는 경우가 자주 발생했다. Jar 파일을 실행할 때 Heap 공간을 너무 적게 준 것이다. 어떻게 해결을 해야 할까 고민 하던 중 당시의 팀장님이 아주 간단한 해결책을 주셨다. 서버를 늘려라.
서버를 늘리는 방법
서버를 늘리는 것은 Scale Up, Scale Out 두 가지 방법으로 접근을 할 수 있다.
Scale Up | Scale Out | |
|---|---|---|
정의 | 서버 한 대의 하드웨어 성능을 업그레이드 한다. 예시) RAM을 16에서 32로 올린다. | 동일한 성능의 서버를 한 대 더 추가한다. |
장점 |
|
|
단점 |
|
|
Scale Up 보다는 Scale Out 을 더 많이 하는 추세이지만, Scale Out이 항상 정답은 아니며, 상황과 서비스에 따라서 증설 방법을 결정해야 한다. 참고로 위에서 마주했던 문제를 해결하기 위해서는 Scale Up을 선택했다.
당시에는 수동으로 Scale Up을 했지만 클라우드에서 제공하는 Auto Scaling을 사용했다면 더 우아한 대처가 될 수 있었을텐데 아쉬움이 남는다.
트래픽의 종류
서버를 늘려야 하는 이유 중 제일 큰 이유는 몰린 트래픽을 처리하기 위해서이다. 그런데 Scaling을 살펴보던 중 트래픽에도 종류가 있다는 걸 발견했다. 바로 North-South 트래픽과 East-West 트래픽이다.
East-West 트래픽
- Server to Server 트래픽이다.
- 데이터 센터 내부에서 발생하는 내부 트래픽이다.
North-South 트래픽
- Client to Server 트래픽이다.
- 데이터 센터와 나머지 네트워크 사이에서 일어나는 트래픽이다. 내부 트래픽을 제외한 나머지 트래픽이라고 생각하면 된다.
요즘은 빅데이터와 MSA 클라우드 환경으로 인해 East-West 트래픽이 훨씬 많아졌다고 한다. 때문에 과거에는 North-South 트래픽을 관리하는 게 쟁점이었지만 요즘은 East-West 트래픽을 관리하는 게 쟁점이다.
로드밸런서가 클라우드 시대의 필수 교양인 이유는?
서버를 아무리 증설한다고 해도 요청을 적절하게 분산해서 서버에게 전달해주는 로드밸런서 없이는 무용지물이다. 클라우드 시대에 서버를 Scale Up 하거나 Scale Out 하기가 굉장히 쉬워진 이 때, 로드밸런서에 대해 알고 있다면 더 효율적으로 서버를 운용하고 대용량의 트래픽을 잘 다룰 수 있을 것이다. 긴 Intro를 지나 이제 로드밸런서에 대해 알아보자.
로드밸런서
일반적인 웹 트래픽 분산처리 구조에서 로드밸런서는 클라이언트와 서버 사이에 존재한다. 때문에 클라이언트의 요청을 제일 처음으로 만나게 된다. 로드밸런서가 클라이언트의 요청을 나눠 각 서버에 할당하면 웹서버 - WAS 서버로 전달이 되어 클라이언트에게 보낼 응답이 만들어진다.
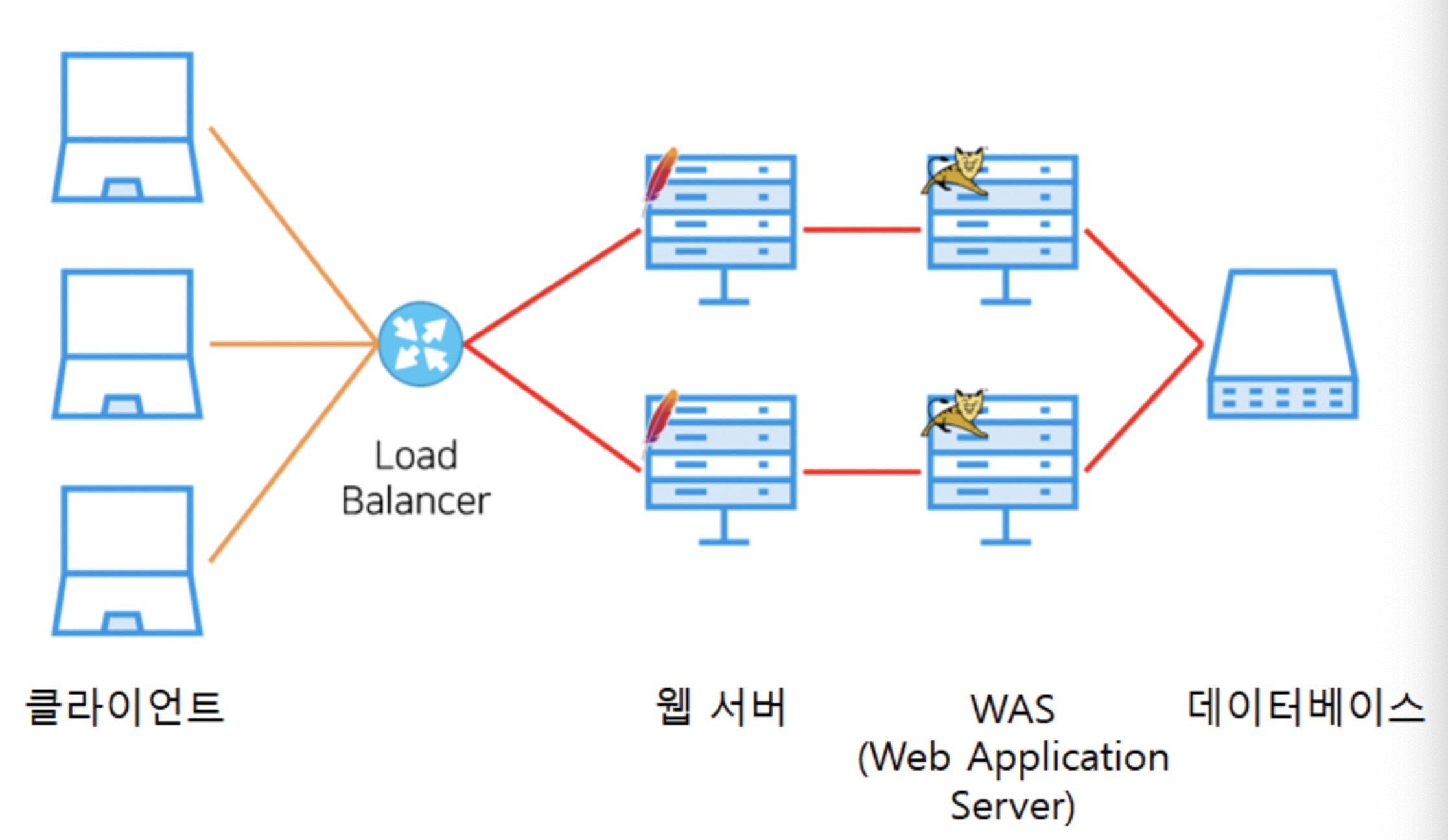
로드밸런서의 기능
- 클라이언트 요청들을
분산해서 서버 그룹에 넘겨준다. 또한 선택된 서버가 만들어낸 응답을 적합한 클라이언트에 리턴해준다. - 서버의 핼스체크가 가능하기 때문에 만약 서버가 다운 되었다면, 이를 감지 해 다른 서버로 넘겨준다.
- 클라이언트가 볼 수 있는 에러를 줄여 UX를 향상시킬 수 있다고 한다.
로드밸런서와 session
몇몇 로드밸런서는 session을 영속적으로 관리한다. 세션을 관리함에 따라 특정 클라이언트에게서 온 모든 요청을 동일한 서버에 보낼 수 있다. HTTP는 이론상 stateless 하게 움직이지만, 많은 서비스에서는 주요 기능을 위해 state 를 저장한다.
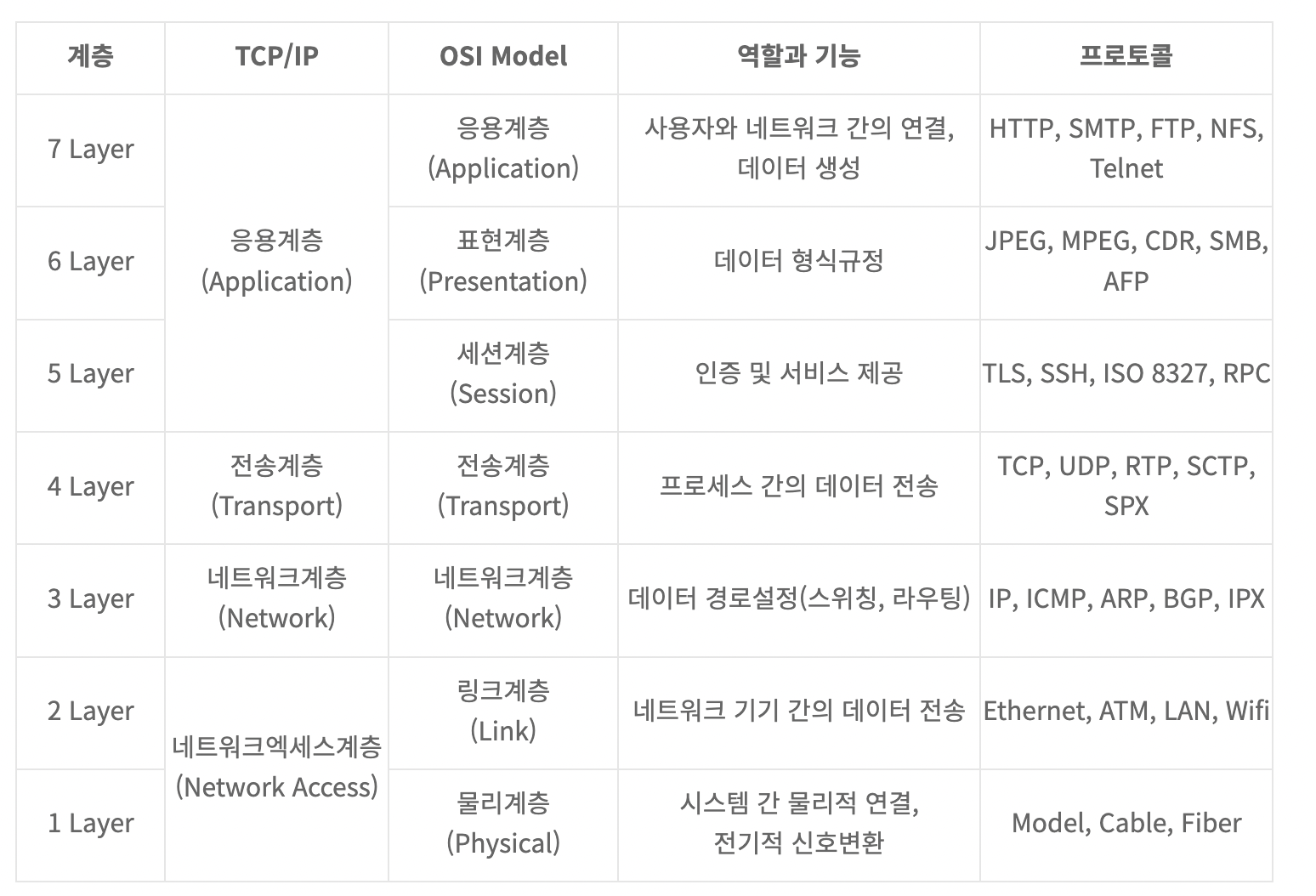
로드밸런서 종류 with OSI 7 계층
로드밸런서는 OSI 7 계층에 걸쳐 여러 종류가 있다. 트래픽은 네트워크를 타고 움직이며, 로드밸런서는 이 트래픽을 분산하는 역할이니 어떻게 보면 네트워크 프로토콜 마다 존재하는 게 당연하게 보인다. 로드밸런서의 네이밍 컨벤션 또한 L(Layer) + 계층 의 형태로 되어있다.
[참고] OSI 7 계층
로드밸런서 종류
종류 | 설명 |
|---|---|
L2 |
|
L3 |
|
L4 |
|
L7 |
|
계층이 올라갈수록 정교한 로드밸런싱이 가능하고, 상위계층 스위치는 하위계층 스위치가 이해할 수 있도록 변환을 해줘야 하기 때문에 상위계층 스위치는 하위계층이 하는 일을 할 수 있다. 결국 해당 계층의 스위치는 자신이 속한 계층 말도고 다른 하위 층에서 사용할 수 있다. 예를 들어 L7을 L4 자리에 배치해도 된다. 다만 자원낭비가 될 뿐이다.
로드밸런싱 알고리즘
Round-Robin (default)
- 가장 간단한 방식의 알고리즘으로, 로테이션을 돌려서 요청을 서버에게 할당한다.
- 서버의 특징 (성능, 유효성 등) 을 고려하지 않고 모두 동일하다 생각하고 할당한다.
Least-Connection
- 새로운 요청이 오면 가장 적은 수의 active 커넥션을 가지고 있는 서버에게 요청을 할당한다.
- Round-Robin 처럼 서버의 특징을 고려하지 않고 할당한다.
ip-Hash
- 새로운 요청을 어떤 서버에게 할당해야 하는지 판단하기 위해 hash function을 이용한다.
- 이때의 hash는 client ip 주소를 기반으로 한다.
여기서 부터는 Nginx에서 제공하지 않는 알고리즘이다.
Weighted Round-Robin
- 서버의 성능을 고려하여 각 서버마다
weight를 설정한다. - weight에 따라 성능이 더 좋은 서버가 있으면 더 많은 요청을 해당 서버에 할당한다.
Weighted Least-Connection
- 서버들의 성능을 고려하여 weight를 주면서 가장 연결이 덜 된 서버에게 요청을 할당한다.
Lease Response Time
- 가장 적은 수의 active 요청을 가지고 있으면서 가장 짧은 응답시간을 보이는 서버에게 요청을 할당한다.
NLB & ALB
aws에서 제공하고 있는 서비스이기 때문에 aws에 한정된 용어이다.
NLB는 Network Load Balancer의 약자이고 ALB는 Application Load Balancer의 약자이다. 본 문서에는 다루지 않았으나 CLB 라는 용어도 있는데 Classic Load Balancer의 약자이다. 그리고 이 모든 Load Balancer 서비스를 묶어서 ELB 라고 하는데 Elastic Load Balancer의 약자이다.
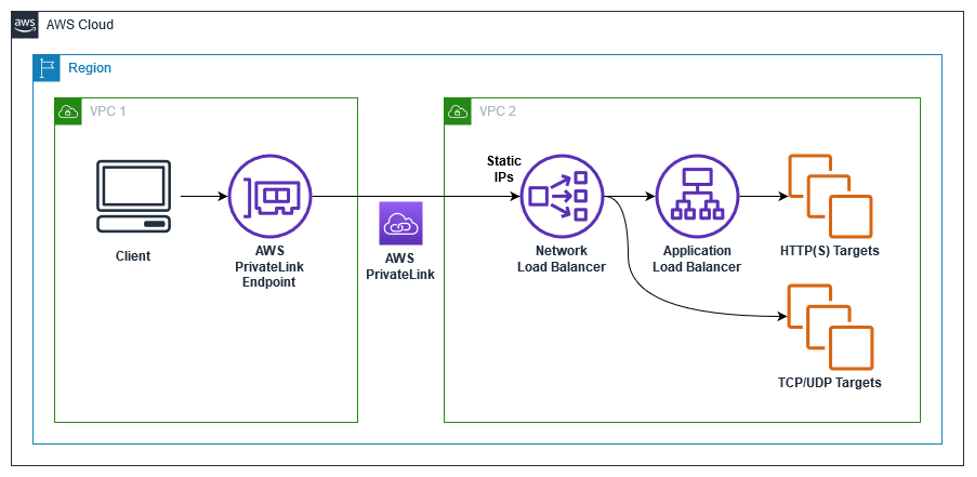
NLB
특징
TLS/TCP/UDP트래픽을 담당하며 static ip를 사용하여 고정적이다.- 별도의 판단 기준 없이 요청을 포워드 해주는 일만 한다. 단순한 만큼 퍼포먼스가 매우 좋다.
- 모든 어플리케이션을 동일하게 본다. 크러쉬가 나거나 오프라인인 어플리케이션에 요청을 할당할 때 도 있다.
- 어플리케이션의 유효성을 판단할 수 없다. TCP 계층을 기준으로 판단하기 때문이다.
- 서버에 ICMP ping을 날려서 응답이 오는지 안 오는지로 판단한다.
- 또는 3 way handshaking을 완벽하게 끝났는지로 판단한다.
용도
- real-time 데이터 스트리밍 서비스 (비디오, 주식시세) 에 사용한다.
- HTTP 프로토콜이 아니거나, ALB가 통하지 않을 상황일 때 사용한다.
ALB
특징
HTTP/HTTPS트래픽을 담당하며 유연하다.- HTTP 헤더 컨텐츠를 보고 요청을 어디로 라우트 해야 하는지 판단한다. 이를
Content Based Routing이라 한다. - 어플리케이션의 유효성을 깊게 판단할 수 있다.
- 특정 페이지의 HTTP GET을 성공적으로 가져왔는지 판단한다.
- 리턴된 컨텐츠가 인풋 파라메터 기준으로 expected 된 게 맞는지 까지 검증한다.
용도
- 웹 어플리케이션에 사용할 수 있다.
- MSA에서 EC2나 도커의 앞에서 내부 로드밸런서로 사용할 수 있다.
- REST API 어플리케이션 앞에서 쓸 수 도 있는데 이보다는
AWS API Gateway를 쓰는 게 더 좋은 성능을 낸다.
(plus) 리버스 프록시
Nginx를 다루면서 로드밸런서와 리버스 프록시가 많이 헷갈렸다. 클라이언트와 서버 사이에 위치하고, 요청을 포워딩하고,응답을 클라이언트에 전달한다는 개념이 유사해서 혼동이 왔었다. 때문에 둘의 개념을 한 번 다루고 가면 좋을 거 같아 리버스 프록시 내용을 추가했다.
로드밸런서와 리버스 프록시의 차이
로드밸런서는 클라이언트의 요청을 분산하는 것에 집중하고 있다면 리버스 프록시는 클라이언트의 요청을 actual processing을 위해 서버로 포워딩해도 되는지 판단하는 것에 집중하고 있다.
A
load balancerreceives user requests, distributes them accordingly among a group of servers, then forwards each server response to its respective user.
A
reverse proxyfacilitates a user’s requests to a web server/application server and the server’s response.
리버스 프록시의 기능
- 클라이언트 요청들을
판단해서 서버 그룹에 넘겨준다. 또한 선택된 서버가 만들어낸 응답을 적합한 클라이언트에 리턴해준다. - 웹사이트의
public face와 같다. 리버스 프록시 주소는 하나의 공개된 웹사이트고, 이 주소는 사이트 네트워크의 가장 끝단에 위치하고 있다. 그래서 브라우저나 모바일의 요청이 모두 이 끝단에 모이게 된다. - 로드밸런서는 여러 대의 서버가 있을 때 사용이 가능하지만 리버스 프록시는 하나의 웹서버 또는 하나의 WAS 서버만 있어도 사용이 가능하다.
리버스 프록시의 장점
보안
- 네트워크 밖으로 백엔드 서버가 노출이 안되기 때문에 malicious 한 클라이언트가 취약점에 대해 다이렉트로 접근할 수 없다.
- 많은 리버스 프록시가 서버를
DDoS로 부터 보호하는 기능을 포함하고 있다. 특정 IP로부터 오는 트래픽을블랙리스트로 설정해 거부하거나, 클라이언트가 사용하는 커넥션의 수를 제한하는 방식 등이 여기에 해당한다.
확장성과 유연성 증가
- 클라이언트는 리버스 프록시의 IP만 알고 있기 때문에 내부에서 마음대로 백엔드 인프라를 변경할 수 있다.
- load-balanced 환경에서 트래픽 볼륨에 따라서 서버를 늘이고 줄일 때 특히 유용하다.
- 리버스 프록시는 로드밸런싱도 한다.
웹 가속화 (acceleration)
압축: 클라이언트에게 응답을 보내기 전에 압축을 한다. 압축을 통해서 bandwidth를 줄이고 네트워크에서 빠르게 이동하도록 만든다.SSL Termination: 서버와 클라이언트 사이의 트래픽은 암호화가 되어야 하는데 때때로 암호화는 부담이 될 수 있다. 이때 리버스 프록시가 암호화와 복호화를 담당해서 부담을 덜어준다.캐싱: 서버의 응답을 클라이언트에게 보내기 전에 리버스 프록시는 응답을 로컬에 저장한다. 그래서 동일한 요청이 들어왔을 때 서버로 가지 않고 캐싱한 응답을 전달한다.