Breet Slatkin의 저서 [Effective Python]을 요약한다. 이 포스트에서는 PEP8, bytes and str, f formatter, range, enumerate, zip를 다룬다.
Index
- Better way 1 사용중인 파이썬의 버전을 알아두라
- Better way 2 PEP8 스타일 가이드를 따르라
- Better way 3 bytes와 str의 차이를 알아두라
- Better way 4 C 스타일 형식 문자열을 str.format과 쓰기보다는 f-문자열을 통한 인터플레이션을 사용하라
- Better way 5 복잡한 식을 쓰는 대신 도우미 함수를 작성하라
- Better way 6 인덱스를 사용하는 대신 대입을 사용해 데이터를 언패킹하라
- Better way 7 range보다는 enumerate를 사용하라
- Better way 8 여러 이터레이터에 대해 나란히 루프를 수행하려면 zip을 사용하라
- Better way 9 for나 while 루프 뒤에 else 블록을 사용하지 말라
- Better way 10 대입식을 사용해 반복을 피하라
Better way 1 사용중인 파이썬의 버전을 알아두라
파이썬 버전 콘솔 명령어 예시
|
|
파이썬 버전 코드 예시
|
|
파이썬2
파이썬2는 2020년 1월 1일부로 수명이 다했다. 이제 더이상 버그수정, 보안 패치가 이뤄지지 않는다. 공식적으로 지원을 하지 않은 언어이기 때문에 사용에 대한 책임은 개발자에게 따른다.
파이썬2로 작성된 코드를 사용해야 한다면 2to3, six와 같은 라이브러리의 도움을 받아야 한다.
six 사용 예시
|
|
Better way 2 PEP8 스타일 가이드를 따르라
PEP8는 파이썬 코드를 어떤 형식으로 작성할지 알려주는 스타일 가이드다. 문법만 올바르다면 어떤 방식으로 원하든 파이썬 코드를 작성해도 좋지만, 일관된 스타일을 사용하면 코드에 더 친숙하게 접근하고, 코드를 더 쉽게 읽을 수 있다.
PEP8 스타일 가이드
공백
- 탭 대신 스페이스를 사용해 들여쓰기를 하라.
- 문법적으로 중요한 들여쓰기에는 4칸 스페이스를 사용하라.
- 라인 길이는 79개 문자 이하여야 한다.
- 긴 식을 다음 줄에 이어서 쓸 경우에는 일반적인 들여쓰기보다 4스페이스를 더 들여써야 한다.
- 파일 안에서 각 함수와 클래스 사이에는 빈 줄 두 줄 넣어라.
- 클래스 안에서 메서드와 메서드 사이에는 빈 줄을 한 줄 넣어라.
- dict에서 키와 콜론(:) 사이에는 공백을 넣지 않고, 한 줄 안에 키와 값을 같이 넣는 경우에는 콜론 다음에 스페이스를 하나 넣는다.
- 변수 대입에서 = 전후에는 스페이스를 하나씩만 넣는다.
- 타입 표기를 덧붙이는 경우에는 변수 이름과 콜론 사이에 공백을 넣지 않도록 주의하고, 콜론과 타입 정보 사이에는 스페이스를 하나 넣어라.
공백 예시
|
|
명명 규약 (name convention)
함수, 변수, 애트리뷰트 명명 규약
- 함수, 변수, 애트리뷰트는 lowercase_underscore 처럼 소문자와 밑줄을 사용해야 한다.
- snake case
- 모듈 수준의 상수는 ALL_CAPS처럼 모든 글자를 대문자로 하고, 단어와 단어 사이를 밑줄로 연결한 형태를 사용한다.
private 명명 규약
- 보호해야(protect) 하는 인스턴스 애트리뷰트는 일반적인 애트리뷰트 이름 규칙을 따르되, 밑줄로 시작한다.
- private 인스턴스 애트리뷰는 밑줄 두 줄로 시작한다.
- 밑줄 두 줄은 maigc method를 위한 컨벤션인줄 알았는데, 클래스에서 private 메소드와 애트리뷰트를 밑줄 두줄로 만든다.
- 파이썬에서 private, protect 모두 정식 지원을 하지 않기 때문에, 가독성을 위한 네임 컨벤션에 더 가깝다.
클래스 명명 규약
- 클래스와 예외는 CapitalizedWord 처럼 여러 단어를 이어 붙이되, 각 단어의 첫 글자를 대문자로 만든다.
- PascalCase, CamelCase
- 클래스에 들어있는 인스턴스 메서드는 호출 대상 객체를 가리키는 첫번쨰 인자의 이름으로, 반드시 self를 사용해야한다.
- 자기자신을 가르키기 때문에
- 클래스 메서드는 클래스를 가르키는 첫 번째 인자의 이름으로 반드시 cls를 사용해야 한다.
- 클래스 자체를 가르키기 때문에
함수, 변수 명명 예시
|
|
private 인스턴스 명명 예시
|
|
식과 문
읽기 쉬운 식 작성
- 긍정적인 식을 부정하지 말고, 부정을 내부에 넣어라.
- 한 줄짜리 if 문이나 한 줄짜리 for, while 루프, 한 줄 짜리 except 복합문을 사용하지 말라. 명확성을 위해 각 부분을 여러 줄에 나눠 배치하라.
- 식을 한 줄 안에 다 쓸 수 없는 경우, 식을 괄호로 둘러싸고 줄바꿈과 들여쓰기를 추가해서 읽기 쉽게 만들라.
- 여러 줄에 걸쳐 식을 쓸 때는 줄이 계속된다는 표시를 하는 \ 문자 보다는 괄호를 사용하라.
- editor를 사용하다보면 이렇게 \ 되는 형식을 많이 사용하는데, PEP8에서 권장하지 않은 형태였다니, 앞으로 ()를 써보도록 노력하겠다.
빈 컨테이너 확인
- 빈 컨테이너나 시퀸스([], ‘’)등을 검사할 때는 길이를 0과 비교하지 말라. 빈 컨테이너나 시퀸스 값이 암묵적으로 False 취급된다는 사실을 활용해라.
- 파이썬을 자바와 동실시 해서, 얼마전에 str ≠ ‘’ 로 비어있는 여부를 검사한 적이 있다. 파이썬에서 비어있는 str는 False 취급이라는 것을 꼭 기억하자.
- 마찬가지로 비어 있지 않은 컨테이너나 시퀸스([1], ‘hi’) 등을 검사할 때는 길이를 0과 비교하지 말라. 컨테이너가 비어있지 않은 경우 암묵적으로 True 평가가 된다는 사실을 활용해라.
내부 부정 예시
|
|
빈 컨테이너 확인 예시
|
|
임포트
임포트 문은 평소에 정말 신경을 쓰지 않았는데, 앞으로는 editor에서 어떻게 임포트를 하는지 보고, 신경 써서 작성하도록 하자.
- import 문을 항상 파일 맨 앞에 위치시켜라.
- 모듈을 임포트할 때는 절대적인 이름을 사용하고, 현 모듈의 경로에 상대적인 이름은 사용하지 말라.
- 반드시 상대적인 경로로 임포트를 해야 하는 경우에는 명시적인 구문을 사용하라.
임포트 순서
- 임포트를 적을 때는 아래와 같은 순서로 섹션을 나누고, 각 세션은 알파벳 순서로 모듈을 임포트하라.
- 표준 라이브러리 모듈
- 서드 파티 모듈
- 여러분이 만든 모듈
임포트 예시
|
|
상대 경로 임포트 예시
|
|
결론
개인 프로젝트를 할 때에도 pylint, flake8 등의 파이썬 lint를 이용해서 스타일을 준수하도록 노력하자.
Better way 3 bytes와 str의 차이를 알아두라
파이썬에는 문자열 데이터의 시퀸스를 표현하는 두 가지 타입 bytes와 str이 있다.
bytes
부호가 없는 8바이트 데이터가 그대로 들어가거나, 아스키 인코딩을 사용해 내부 문자를 표시한다.
bytes 예시
|
|
str
사람이 사용하는 언어의 문자를 표현하는 유니코드 코드 포인트가 들어간다.
인코딩
str에는 직접 대응하는 이진 인코딩이 없고, bytes에는 직접 대응하는 텍스트 인코딩이 없다.
때문에 함수를 호출해야 한다.호출 할 때 여러분이 원하는 인코딩 방식을 명시적으로 지정할 수 도 있고 시스템 디폴트 인코딩을 사용할 수 있는데 일반적으로 utf-8이 시스템 디폴트다.
인코딩 시나리오
- 유니코드 데이터를 이진 데이터로 변환해야 할 때:
str의encode메서드 호출 - 이진 데이터를 유니코드 데이터로 변환해야 할 때:
bytes의decode메서드 호출
유니코드 샌드위치
유니코드 데이터를 인코딩하거나 디코딩하는 부분을 인터페이스의 가장 먼 경계 지점에 위치시켜라. 이런 방식을 유니코드 샌드위치라고 부른다.
프로그램의 핵심 부분은 유니코드 데이터가 들어 있는 str를 사용해야 하고, 문자 인코딩에 대해 어떤 가정도 해서는 안된다.
- 핵심 함수에는 이미 인코딩이 된 str이 인자로 전달되어야 한다.
- 이런 접근을 하면 다양한 텍스트 인코딩으로 입력 데이터를 받아들일 수 있고, 출력 텍스트 인코딩은 한 가지로 엄격하게 제한할 수 있다.
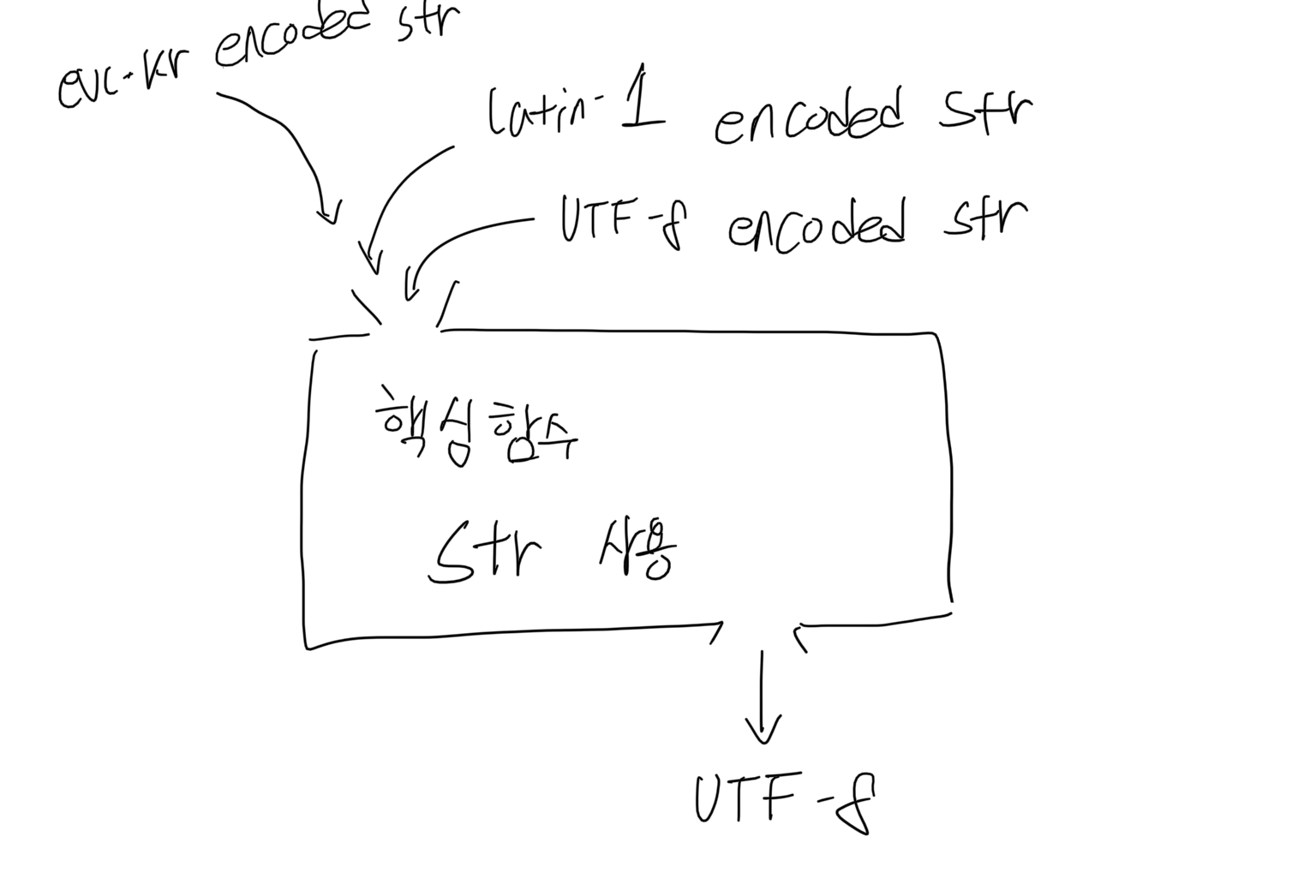
str 반환 유니코드 샌드위치 예시
|
|
bytes 반환 유니코드 샌드위치 예시
|
|
파이썬에서 bytes와 str을 다룰 때 기억해야 하는 점
연산
bytes와 str이 똑같이 작동하는 것처럼 보이지만 각각의 인스턴스는 서로 호환되지 않기 때문에 전달중인 문자 시퀸스가 어떤 타입인지 알아야 한다.
연산 불가항목 예시
|
|
파일
(내장함수 open을 호출해 얻은) 파일 핸들과 관련한 연산들이 디폴트로 유니코드 (str) 문자열을 요구하고, 이진 바이트 문자열을 요구하지 않는다.
이진 쓰기 모드 (’wb’)가 아닌 텍스트 쓰기 모드 (’w’) 로 열면 오류가 난다. bytes로 파일 읽기, 쓰기를 하고 싶다면 이진 읽기모드 (’rb’) 또는 이진 쓰기모드 (’wb’)를 써야 한다.
파일 불가항목 예시
|
|
파일 시스템의 디폴트 텍스트 인코딩을 bytes.encode(쓰기), str.decode(읽기) 에서 사용하는데 utf-8이기 때문에 이진데이터의 경우 utf-8로 읽지 못하는 경우가 생겨 에러가 발생할 수 있다.
이런 현상을 막고자, utf-8로 인코딩을 못하는 경우에는 읽어올 때 인코딩을 아예 명시해주는 경우도 있다.
인코딩 명시 예제
|
|
결론
시스템 디폴트 인코딩을 항상 검사하도록 하자.
|
|
Better way 4 C 스타일 형식 문자열을 str.format과 쓰기보다는 f-문자열을 통한 인터플레이션을 사용하라.
형식화는 미리 정의된 문자열에 데이터 값을 끼워 넣어 사람이 보기 좋은 문자열로 저장하는 과정이다. 파이썬에서는 f-문자열을 통한 인터플레이션 빼고는 각자의 단점이 있다.
형식 문자열
% 형식화 연산자를 사용한다. 왼쪽에 들어가는 미리 정의된 텍스트 템플릿을 형식 문자열이라고 부른다. C 함수에서 비롯된 방법이다.
형식 문자열 예시
|
|
형식 문자열 문제점
- 형식화 식에서 오른쪽에 있는 값들의 순서를 바꾸거나, 타입을 바꾸면 포멧팅이 안되어 오류가 발생한다.
- 형식화를 조금이라도 변경하면 식이 매우 복잡해 읽기가 힘들다.
- 같은 값을 여러번 사용하고 싶다면 오른쪽 값을 여러번 복사해야 한다.
내장 함수 format과 str.format
파이썬 3부터는 %를 사용하는 오래된 C스타일 형식화 문자열보다 더 표현력이 좋은 고급 문자열 형식화 기능이 도입됐다. 이 기능은 format 내장 함수를 통해 모든 파이썬 값에 사용할 수 있다.
format 예시
|
|
format 문제점
- C 스타일의 형식화와 마찬가지로, 값을 조금 변경하는 경우에는 코드 읽기가 어려워진다. 가독성 면에서 거의 차이가 없으며, 둘 다 읽기에 좋지 않다.
인터폴레이션을 통한 형식 문자열 (f-문자열)
위의 문제들을 완전히 해결하기 위해 파이썬 3.6 부터는 인터폴레이션을 통한 형식 문자열 (짧게 f-문자열)이 도입되었다. 이 새로운 언어 문법에서는 형식 문자열 앞에 f 문자를 붙여야 한다. 바이트 문자열 앞에 b 문자를 붙이고, raw 문자열 앞에 r문자를 붙이는 것과 비슷하다.
f-문자열은 형식화 식 안에서 현재 파이썬 영역에서 사용할 수 있는 모든 이름을 자유롭게 참조할 수 있도록 허용함으로써 이런 간결함을 제공한다.
f-문자열 예시
|
|
파이썬에서 제공하는 형식화 문법의 차이 예시
|
|
결론
f-문자열은 간결하지만, 위치 지정자 안에 임의의 파이썬 식을 직접 포함시킬 수 있으므로 매우 강력하다. 값을 문자열로 형식화해야 하는 상황을 만나게 되면 다른 대안 대신 f-문자열을 택하라.
복잡한 식을 쓰는 대신 도우미 함수를 작성하라.
파이썬은 문법이 간결하므로 상당한 로직이 들어가는 식도 한 줄로 매우 쉽게 작성할 수 있다. 예를 들어 URL의 query string를 파싱하고 싶다고 하자.
query string 파싱 예시
|
|
이런 때에 파라미터가 없거나 비어 있을 경우 0이 디폴트 값으로 대입되면 좋을 것이다. 여러 줄로 작성해야 하는 if 문(if statement)를 쓰거나 도우미 함수를 쓰지 않고, if 식(if expression)으로 한줄로 처리 할 수 있다.
뿐만 아니라, 모든 파라메터 값을 정수로 변환해서 즉시 수식에서 활용하기를 바란다고 해보겠다. 그럼 식은 아래와 같아진다.
한 줄 대입, 변환 예시
|
|
현재 이 코드는 너무 읽기 어렵고 시각적 잡음도 많다. 즉, 코드를 이해하기 쉽지 않으므로 코드를 새로 읽는 사람이 이 식이 실제로 어떤 일을 하는지 이해하기 위해 너무 많은 시간을 투자해야 한다.
코드를 짧게 유지하면 멋지기는 하지만, 모든 내용을 한줄에 우겨 넣기 위해 노력할 만큼의 가치는 없다.
명확하게 바꾼 코드 예시
|
|
식이 복잡해지기 시작하면 바로 식을 더 작은 조간으로 나눠서 로직을 도우미 함수로 옮길지 고려해야 한다. 특히 같은 로직을 반복해 사용할 때는 도우미 함수를 꼭 사용하라. 아무리 짧게 줄여 쓰는 것을 좋아한다 해도, 코드를 줄여 쓰는 것보다 가독성을 좋게 하는 것이 더 가치 있다.
결론
파이썬의 함축적인 문법이 지저분한 코드를 만들어내지 않도록 하라. 반복하지 말라는 뜻의 DRY 원칙을 따르라.
Better way 6 인덱스를 사용하는 대신 대입을 사용해 데이터를 언패킹하라
파이썬에서는 언패킹 구문이 있다. 언패킹 구문을 사용하면 한 문장 안에서 여러 값을 대입할 수 있다. 교재에서는 튜플을 사용할 때 인덱스 말고 언패킹을 사용하는 예제를 보여주고 있다. 언패킹은 튜플 인덱스를 사용하는 것보다 시각적인 잡음이 적다.
Tuple 언패킹 예시
|
|
언패킹을 이용해서 임시변수 없이 값 맞 바꾸기
|
|
작동원리
- 대입문의 오른쪽 a[i], a[i=1]이 계산된다.
- 그 결과값이 이름없는 새로운 tuple에 저장된다.
- 대입문의 왼쪽에 있는 언패킹 a[i-1], a[i]를 통해 이름없는 tuple에 있는 값이 a[i-1], a[i]에 저장된다.
- 이름없는 tuple이 사라진다.
for 루프와 같은 컴프리헨션, 제너레이터의 리스트 원소를 언패킹하는 방법
|
|
Better way 7 range보다는 enumerate를 사용하라
리스트를 이터레이션하면서 리스트의 몇 번째 원소를 처리 중인지 알아야 할 때가 있다.
range를 사용하면 list의 길이를 알아야 하고, 인덱스를 사용해 배열 원소에 접근해야 한다. 단계가 여러개라 결국 코드가 투박해진다.
range
|
|
enumerate는 이터레이터를 제너레이터로 감싼다. 그리고 호출이 될 때 마다 루프 인덱스와 이터레이터의 다음 값으로 이뤄진 튜플 쌍을 리턴한다.
튜플 형태로 넘겨주니 Better way 6처럼 언패킹을 이용하기도 좋다.
enumerate
|
|
enumarate에서 시작할 루프 인덱스 설정해주기
|
|
Better way 8 여러 이터레이터에 대해 나란히 루프를 수행하려면 zip을 사용하라
enumarate를 사용하여 나란히 루프를 수행
|
|
zip을 사용하여 나란히 루프를 수행
|
|
두 리스트를 동시에 이터레이션 할 경우 내장함수 zip을 사용하면 훨씬 더 깔끔하다.
내장함수 zip
- zip은 둘 이상의 이터레이터를 제너레이터를 사용해 묶어준다.
- zip 제너레이터는 각 이터레이터의 다음 값이 들어있는
튜플을 반환한다. - zip은 자신이 감싼 이터레이터 원소를 하나씩 소비하기 때문에 메모리를 다 소모해서 프로그램이 중단되는 위험 없이 아주 긴 입력도 처리할 수 있다.
여러 이터레이터의 길이가 같지 않을 경우
길이가 같지 않은 리스트를 zip을 사용하여 나란히 루프를 수행
|
|
zip은 자신이 감싼 이터레이터 중 어느 하나가 끝날때까지 튜플을 내놓는다. 따라서 출력은 가장 짧은 입력의 길이와 같다.
리스트들의 길이가 같지 않을 것으로 예상한다면 itertools 내장모듈에 들어있는 zip_longest 를 사용하자.
길이가 같지 않은 리스트를 zip_longest를 사용하여 나란히 루프를 수행
|
|
zip_longest를 사용했을 때 존재하지 않은 값은 fillvalue 를 통해 값을 설정해 줄 수 있다. 디폴트 값은 None이다.
Better way 9 for나 while 루프 뒤에 else 블록을 사용하지 말라
파이썬에서는 루프가 반복 수행하는 내부 블록 바로 다음에 else 블록을 추가할 수 있다. 이 else 블록은 루프가 break를 통해 빠져나가지 않고 끝까지 루프를 했다면 실행이 된다.
서로소 구하기: 루프 뒤에 else를 사용
|
|
if/else문에서 else는 이 블록 앞의 블록이 실행되지 않으면 이 블록을 싱행하라 인데
루프 뒤애 오는 else는 루프가 정상적으로 완료되었다면 실행되기 때문에 마치 and와 같은 역할을 하고 있다. 이름과 역할이 달라 직관적이지 못하다.
루프가 한 번도 돌지 않아도 실행되는 else
|
|
또한 빈 시퀸스나 while 루프 조건이 처음부터 False인 경우에도 else 블록이 실행된다. 빈 시퀸스이거나 while 조건이 처음부터 False이면 루프가 단 한 번도 실행되지 못하는데 말이다.
서로소 구하기 리팩토링
루프 뒤 else를 사용해서 만든 서로소 구하기는 직관적이지 못해 더 직관적이게 도우미 함수를 작성하여 서로소를 구해본다.
서로소 구하기: 원하는 조건을 찾자마자 함수를 반환
|
|
서로소 구하기: 원하는 대상을 찾았는지 나타내는 결과 변수를 도입
|
|
절대로 루프 뒤에 else 블록을 사용하지 말아야 하는 이유
- else 블록을 사용함으로써 얻을 수 있는
표현력보다는 미래에 이 코드를 이해하려는 사람들이 느끼게 될부담감이 더 크다. - 파이썬에서 루프와 같은 간단한 구성 요소는 그 자체로
의미가명확해야 한다.
Better way 10 대입식을 사용해 반복을 피하라
대입식은 파이썬 언어에서 고질적인 코드 중복 문제를 해결하기 위해 파이썬 3.8에서 새롭게 도입된 구문으로 왈러스 연산자 (walrus) 라고도 부른다.
연산자 기호 := 이 마치 바다코끼리 (walrus)의 눈과 엄니를 닮아서 이런 별명이 생겼다.

왈러스 연산자의 장점은 값을 대입할 수 없어 대입문이 쓰일 수 없는 if 조건문 과 같은 위치에 사용할 수 있다는 것이다. 즉, 원래라면 값을 대입할 수 없는 자리에 왈러스 연산자를 씀으로 값을 대입할 수 있다.
왈러스 연산자가 하는 일
- Step 1: 대입
- Step 2: 대입된 값을 평가
월러스 연산자
|
|
왈러스 연산자 용법
왈러스 연산자를 쓰지 않았을 때
|
|
count 변수는 if 문의 첫 번째 블록 안에서만 쓰인다. 하지만 if 앞에서 count를 정의하면서 마치 else 블록이나 그 이후의 코드에서 count 변수에 접근을 할 필요가 있어 보인다. 따라서 실제보다 count 변수가 중요해보인다.
파이썬에서는 이런 식으로 값을 가져와서 그 값이 0이 아닌지 검사한 후 사용하는 패턴이 많다. 왈러스 연산자를 사용해서 가독성을 높이도록 하자.
왈러스 연산자를 썼을 때
|
|
count가 if문의 첫 번째 블록에서만 의미가 있다는 점이 명확하게 보여 코드가 더 읽기 쉬워졌다. 덩달아 코드도 조금 더 짧아졌다.
왈러스 연산자를 이용해 더 중요한 변수에 힘 주기
이 패턴은 더 중요한 변수에 힘을 주기에도 좋지만, if condition에서 값을 비교하고, 해당 스코프 안에서 그 값을 함수 호출할 때 사용했다는 것을 기억하자.
왈러스 연산자를 쓰지 않았을 때
|
|
pieces 가 훨씬 중요한 변수인데 if 앞에서 count 를 정의해서 마치 count 도 중요해보인다.
왈러스 연산자를 썼을 때
|
|
왈러스 연산자를 이용해 우아하게 switch/case 흉내내기
파이썬에는 switch/case 문이 없기 때문에 일반적으로 if, elif, else 문을 사용해서 흉내를 내는 것이 일반적이다. 왈러스 연산자를 쓰지 않는다면 대입하고 평가하는 것이 나눠져있기 때문에 지져분해진다.
왈러스 연산자를 쓰지 않았을 때
|
|
왈러스 연산자를 썼을 때
|
|
왈러스 연산자를 이용해 우아하게 while문 사용하기
왈러스 연산자를 쓰지 않았을 때
|
|
이 코드는 fresh_fruit = pick_fruit() 호출을 두 번 하고 있기 때문에 반복적이다.
while을 무한루프로 만들고 중간에 break를 두는 식으로 fresh_fruit = pick_fruit() 를 한 번 만 호출 할 수 도 있겠지만
while 루프를 맹목적인 무한루프로 만들고, 루프 흐름 제어가 모두 break 문에 달려있어 while 루프의 유용성이 줄어든다.
왈러스 연산자를 썼을 때
|
|
왈러스 연산자 사용을 고려해야 할 때
몇 줄로 이뤄진 코드 그룹에서 같은 식이나 같은 대입문을 여러 번 되풀이하는 부분을 발견하면 가독성을 향상시키기 위해 대입식을 도입하는 것을 고려해 봐야 한다.