MySQL Index에 대해서 알아본다: clustered, non-clustered structure and algorithm. B-Tree, R-Tree. Side effect of index.
Index
- Clustered Index / Non-Clustered Index - Concept
- Clustered Index / Non-Clustered Index - Structure and Index algorithm
- Side effects of Indexes
- Related SQL Command with Indexes
- Reference
리뷰 후에 알게된 부분들
- Non-Clustered Index가 여러 개 생성이 가능하지만 무제한으로 만들 수 있는 것은 아니다.
- 조회는 Clustered Index가 빠르지만, 수정과 입력은 Non-Clustered Index가 빠르다. 왜냐하면 Non-Clustered Index는 물리적인 정렬을 가지고 있지 않아서 새 데이터가 들어와도 순서대로 정렬을 안 해도 된다.
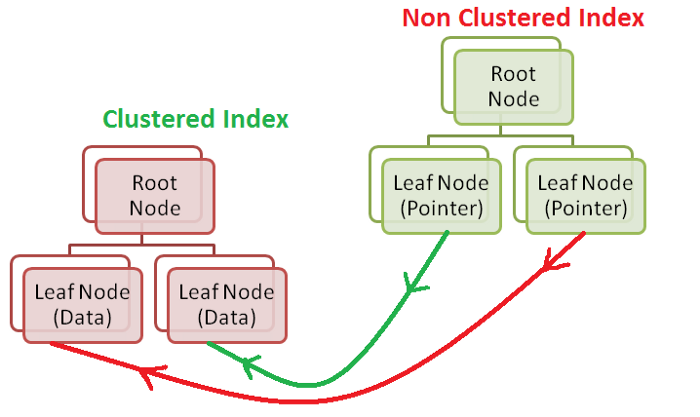
Clustered Index / Non-Clustered Index - Concept
Clustered Index와 Non-Clustered Index 둘 다 테이블에 있는 데이터 엑세스를 빠르게 하기 위한 용도이지만 둘의 성격이 조금 다르다.
가장 큰 차이는 Clustered Index는 테이블 당 딱 1개만 만들어지고, Non-Clustered Index는 복수개가 만들어 질 수 있다는 점과 Clustered Index를 생성하는 Column은 중복을 허용하지 않지만 Non-Clustered Index는 중복을 허용한다는 점이라고 생각한다.
Clustered Index
- Primary Key 로 만들어진다.
- 테이블에 단 하나만 만들 수 있다.
- 중복된 데이터를 허용하지 않는다.
- 테이블에서 데이터를 순서대로 저장하게 해준다.
- 크기가 큰 테이블에서 데이터를 빠르게 찾아오게 하기 위해서 꼭 만들어주는 게 좋다.
- 속도가 Non-Clustered Index 보다 빠르다.
Non-Clustered Index
- Unique Key와 Key 로 만들어 진다.
- Mysql의 일반 Key는 인덱스를 생성하는 역할만 수행한다.
- Unique Key의 특성상 해당 키로 인덱스를 생성했다면 중복값이 있을 수 없다.
- 그래서 Unique Key의 Index를 Unique Non-Clustered Index라고 하기도 한다.
- 테이블에 여러개를 만들 수 있다.
- 중복된 데이터를 허용한다.
- 데이터 저장에 아무런 영향을 미치지 않는다.
- 과도한 Non-Clustered Index 생성은 퍼포먼스를 떨어뜨리기 때문에 잘 설계해서 꼭 필요한 부분만 만들어야 한다.
- 속도가 Clustered Index 보다 느리다.
Clustered Index / Non-Clustered Index - Structure and algorithm
Clustered Index Structure
- 트리 구조로 만들어진다. (B-tree)
- 각 노드에는 실제 데이터가 저장된다.
- 실 데이터를 가지고 있기 때문에 IO 작업이 적어 데이터 찾기가 훨씬 빠르다.
- (1)속도가 빠르고 (2)모든 Column을 필요로 하는 읽기 전용 어플리케이션이라면 Clustered Index를 만들면 된다.
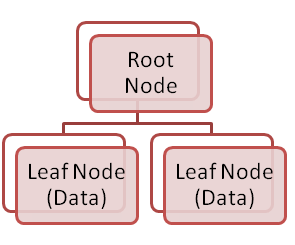
Non-Clustered Index Structure
- 트리 구조로 만들어진다. (B-tree)
- 각 노드에는 포인터 (주소)가 저장되어 있고, 이 주소들은 Clustered Index의 노드들을 가르키고 있다.
- 인덱스 안에 데이터들은 논리적으로 순서를 가지고 있기 때문에 물리적으로는 다른 순서를 가지고 있을 수 있다.
- Index에 해당되는 Column에 따라 논리적으로 정렬이 되어있다.
- Non-Clustered Index를 사용해 검색을 했을 경우 결국 Clustered Index까지 거쳐서 결과가 나오게 된다.
- Clustered Index가 없는 테이블의 Non-Clustered Index는 Heap을 가르킨다.
Heap in MySQL
- Clustered Index를 설정하지 않은 테이블을 Heap이라고 한다.
- Heap은 순서없이 저장된 데이터들을 가지고 있다.
- Heap은 순서를 신경쓰지 않아 크기가 크고, 순서가 중요하지 않은 데이터들의 Insert 연산이 필요한 테이블에 사용된다.
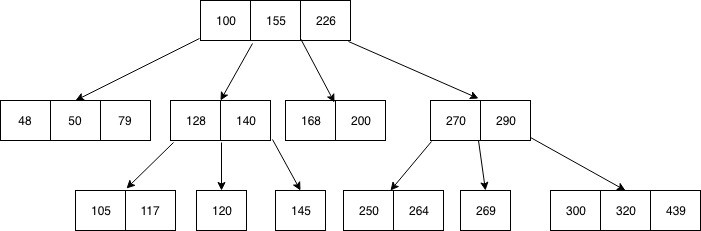
Index algorithm
B-Tree
- O(logN)의 시간 복잡도를 가진다.
- 하나의 노드에 여러가지 데이터를 가질 수 있고, 때문에 참조 포인터가 적어 빠른 메모리 접근이 가능하다.
- 탐색 뿐 아니라 수정과 저장에서도 O(logN)의 시간복잡도를 가진다.
B-Tree를 쓰는 이유
- 시간복잡도가 O(1)인
Hash대신에 O(logN) 시간이 걸리는 B-tree를 사용하는 이유는 Hash는 Key값을 가지고 단 하나의 데이터에 엑세스 하기 때문이다.- 그래서 연산에서 동일한 값을 찾아내는 = 만 사용이 가능하고, 대소비교를 하거나 Between 을 사용할 수 없게 된다.
- 데이터 엑세스가 빠른
배열을 사용하지 않고 포인터로 분산되어있는 B-Tree를 쓰는 이유는 배열은 탐색을 할 때만 빠르고 다른 연산에 대해서는 B-Tree보다 더 느리기 때문이다.
R-Tree
- 공간 정보 탐색을 위한 알고리즘 (기하학)
- Mysql에서 공간정보를 관리하는 타입인 Geometry와 하위 타입들에서 쓰인다고 한다.
- [R-Tree 알고리즘]
Side effects of Indexes
- Clustered Index가 있으면 데이터를 Insert/update 할 때 마다 순서대로 다시 정렬을 해줘야 하기 때문에 속도가 느리다.
- Non-Clustered Index는 디스크에 분산이 되어 저장이 되는데 인덱스를 만들 때 Column 값이 중복으로 저장이 되기 때문에 디스크 낭비가 발생할 수 있다.
- Index를 너무 많이 만들어두면 오히려 탐색 성능까지 떨어지게 된다.
탐색 성능 저하 시나리오
INDEX1는 A와 B Column을 가지고 있고, INDEX2는 A와 C Column을 가지고 있다. 이런 경우 디스크에는 B가 2 번 기록이 된다. 이런 상태에서 B와 C를 조회한다면 INDEX 1,2 를 둘 다 사용해서 포인터를 찾고, 테이블에 있는 데이터를 찾기 시작한다.
Related SQL Command with Indexes
인덱스와 관련된 Command는 DML이 아니라 DDL (Date Define Language) 다!
인덱스 쿼리 예시
|
|
EXPLAIN 쿼리
EXPLAIN 쿼리를 사용하면 작성한 쿼리의 성능과 index 사용 여부 등을 자세히 알 수 있다.
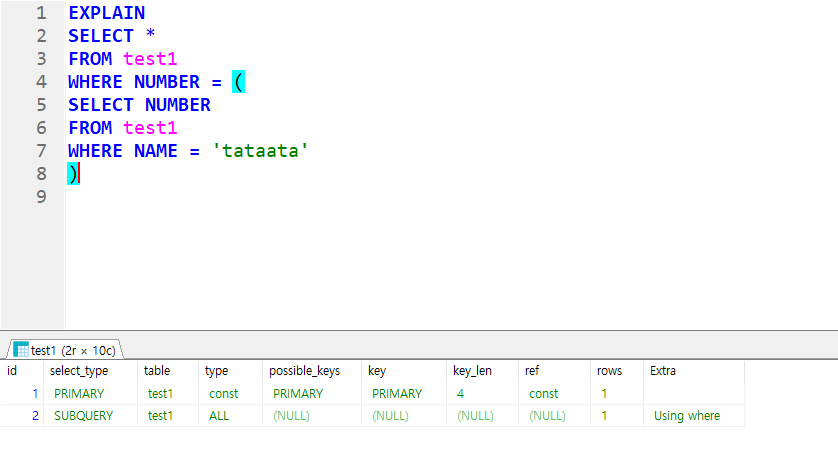
Id
- SELECT 문의 순서
- 서브 쿼리가 있을 경우 순서를 부여해준다.
select_type
- SELECT 문의 유형
SIMPLE: UNION이나 서브 쿼리를 사용하지 않은 SELECTPRIMARY: 서브 쿼리를 사용했을 때 제일 바깥에 있는 SELECTSUBQUERY: 서브쿼리 SELECTDERIVED: FROM 절에 서브쿼리가 있는 SELECT
type
- SELECT 문을 실행하기 위해 테이블을 어떻게 조회했는지를 나타낸다.
ALL: table full scan, 테이블을 처음부터 끝까지 조회했다. (제일 나쁨)INDEX: index full scan, 인덱스를 처음부터 끝까지 조회했다.RANGE: 특정 범위 안에서 인덱스를 사용해서 조회했다.INDEX_MERGE: 두 개의 인덱스를 병합해서 조회했다.REF: 조인을 할 때 Primary 나 Unique 가 아닌 Key로 매칭해서 조회했다.CONST: 매칭되는 row가 단 한 건이며, Primary 나 Unique를 사용해서 조회했다.
possible_keys
- 해당 Column을 찾기 위해 사용된 인덱스
- 이 값이 NULL이라면 사용된 인덱스가 없는 것이다. (이걸 보고 인덱스를 타게 수정이 가능하다)
- key
- 최적화를 위해 Mysql 옵티마이저가 사용하기로 결정한 인덱스
ref
- 데이터를 추출하기 위해 키와 함께 사용된 컬럼 또는 상수
rows
- 쿼리를 수행하기 위해 검색해야 할 Row의 갯수
Extra
- Mysql 옵티마이저가 추가로 해석한 정보.
using index: 인덱스를 이용해 자료 추출using where: where 조건으로 데이터를 추출, 만약 type이 NULL인데 이 값이 나왔다면 쿼리 성능이 좋지 않다는 뜻using temporary: 쿼리 안에서 임시 테이블을 생성/사용using filesort: 데이터 정렬 연산이 포함됨.