
[MySQL] (1)Structured Query Language & Key (2) Collation
by Jamie Lee
리뷰 후에 알게된 부분들
- Primary Key가 들어간 column 의 이름도 아닌 제약조건에 이름을 만드는 이유 -> 주임님이 주신 의견: 기본키를 항상 하나의 column으로 만드는 건 아니고 여러가지 키를 섞어서 만들었을 때 보기 편하게 하기 위해.
- Charset = Symbol (A, B 등 plain text) + encoding
- mysql 에서 지원하는 Collation을 쿼리할 때 나오는
pad-attribute란 무엇인가? -> 가변형인 VARCHAR 말고 CHAR 형의 텍스트를 비교할 때 뒤에 공백을 넣어서 비교하는지 아닌지의 여부. 모든 DB가 그런것은 아니다.
[Reference: MySQL에서 ‘a’ = ‘a ‘가 true로 평가된다?] - 테이블에 걸린 제약조건을 확인하는 방법 (테이블 하나씩 검색하는 방법은 없고 sql 서버 전체에 걸려있는게 나와서 where 절로 뽑아내야 한다)
select * from information_schema.table_constraints;
# use where
select * from information_schema.table_constraints
WHERE CONSTRAINT_SCHEMA = 'test'
- 외래키는 고유하게 식별이 가능한 데이터면 되기 때문에 꼭 primary key말고 unique key를 이용해서도 외래키를 만들 수 있다.
Foreign key should be made with primary key?
index
- Structured Query Language
- DML
- DDL
- DCL (with TCL)
- Key
- DBMS
- Mysql
- Collation
- Reference

Structured Query Language
DML - Data Manipulation Language
- SELECT, INSERT, DELETE, UPDATE
- 데이터를 조작하기 위한 SQL 커맨드
- 개발을 할 때 기본이 되는 CRUD (Create/Read/Update/Delete)이 해당된다.
- 응용프로그램으로 접근할 수 있는 유일한 SQL이다.
DDL - Data Definition Language
- CREATE, ALTER, RENAME, DROP, TRUNCATE
- 데이터베이스의 스키마를 정의/조작 하기 위한 SQL 커맨드
- 데이터베이스의 구조와 제약조건에 대한 전체적인 명세를 가지고 있는 메타성 데이터의 집합을 스키마라고 한다.
- DB에 가장 크리티컬하게 영향을 미치는 커맨드라 DBA나 DB 설계자가 자주 사용하는 커맨드
# ALTER 으로 테이블 이름 변경하기
ALTER TABLE old_name RENAME new_name;
# RENAME 으로 테이블 이름 변경하기
RENAME TABLE old_name TO new_name;
# DROP과 TRUNCATE
# DROP으로 테이블을 지워버리기
DROP TABLE table_name;
# TRUNCATE으로 테이블 초기화하기
TRUNCATE TABLE table_name;
# DROP으로 테이블 초기화하기
DROP TABLE table_name;
CREATE TABLE table_name (
field_name field_type
...
)
Drop은 테이블 자체를 데이터베이스에서 지워버리는데 Truncate은 테이블의 컬럼, 제약조건들은 남겨두고 데이터만 지워준다. DDL인데도 불구하고 응용프로그램에서도 Truncate을 사용하는 경우가 있다고 하는데 응용프로그램에서 테이블의 데이터를 모두 지워버리는 행위는 너무 위험하다고 생각한다. 조건을 이용해서 레코드 하나씩 지워가는 Delete 보다 Truncate이 실행속도는 더 빠르다고 한다.
DCL - Date Control Language
- COMMIT, ROLLBACK, GRANT, REVOKE
- DB의 권한과 무결성을 지키기 휘한 Transaction을 위한 SQL 커맨드
- COMMIT과 ROLLBACK을 따로 빼서 TCL (Transaction Control Language)라고 하기도 한다.
- Transaction은 커맨드를 테스트 할 때 데이터의 변경 없이 테스트를 하고 싶을 때 활용할 수 있다.
START TRANSACTION;
SELECT * FROM users;
DELETE FROM users WHERE NAME = 'jamie';
SELECT * FROM users;
ROLLBACK;
이런식으로 Transaction을 걸면 각 줄이 실행되면서 SELECT로 결과를 보여주고 Rollback 커맨드로인해 테스트를 하기 전의 상태로 데이터베이스가 돌아간다. 일반 SELECT가 아닌 조건이 복잡한 DELETE, UPDATE, INSERT 쿼리를 사용해야 할 때 쓰면 좋아보인다.
그런데 저렇게 짠 쿼리 중에 오류가 있으면 마지막 ROLLBACK까지 오지가 않기 때문에 Transaction 처리가 안된다… 아무리 Transaction을 걸었다고 해도 조심을 해야할 필요가 있어보인다.

Key
키를 생성하면 제약조건이 걸린다. 그럼 키와 제약조건의 차이는 무엇인가?
- 키는 테이블의 단일 필드에 걸거나 복합적인 필드에 걸 수 있다. 또한 테이블에서 조건에 따라 데이터를 가져오기 위해 사용되며 다른 테이블과 뷰 사이의 관계 또한 생성을 할 수 있다. 내가 생각했던 것 처럼 키 자체를 제약조건이라고 보기는 힘들다 .
- 제약조건은 데이블의 데이터를 위한 특정한 규칙들이다. 만약 data action(SQL command로 데이터를 변경하기 위한 action들)이 제약조건을 위배한다면 그 data action을 취소해버린다. 제약조건은 테이블을 생성할 시기나, 생성한 이후에 걸 수 있다.
DBMS
- Primary Key
- 테이블 안에서 중복되지 않은 값을 사용해서 데이터들(row)을 고유하게 식별한다.
- 테이블 안에서 Primary Key 는 하나밖에 있을 수 없다.
- NULL은
absence of value기 때문에 값이라고 할 수 없다. 그래서 Primary Key에 NULL값을 넣을 수 없다. - 또한 물리적인 인덱스를 생성하는데 값이 비어있으면 순서를 정할 수 없어서 NULL값을 넣을 수 없다.
- Primary Key = Unique Constraint + NOT NULL
- Foreign Key가 걸려있으면 Primary Key를 변경할 때 이를 참조하고 있는 Foreign Key까지 함께 변경해줘야 한다. 이떄 ON UPDATE CASCADE 기능을 사용한다.
- Foreign Key
- 테이블들 사이에 관계를 만들고, 참조 무결성을 유지하는데 사용된다.
- 테이블을 연결시켜 주기 때문에 어떤 데이터인지 고유하게 식별이 가능해야 해서 Foreign Key를 만들기 위해서는 Primary Key를 사용해야 한다.
- NULL 값이 들어갈 수 있다.
Foreign Key를 Primary Key로 만드는데 NULL이 들어갈 수 있는 이유는 Foreign Key로 이미 관계는 만들어졌으나 참조하는 테이블에서 Primary Key를 비롯한 데이터가 아직 만들어지지 않았을 수 있기 때문에.
- Super Key
- 테이블에서 데이터를 식별할 수 있게 해주는 Key 또는 Key Set
- 식별만 가능하면 되기 때문에 여러가지 Column들을 조합해서 여러개의 Super Key 를 만들 수 있다.
- Primary Key도 Super Key 에서 뽑힌다.
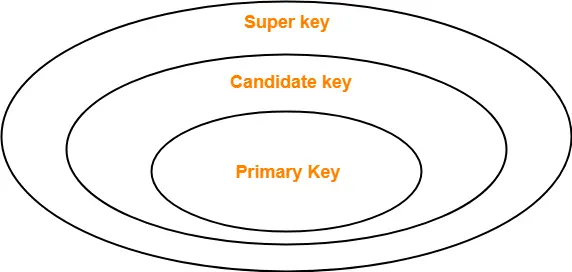
- Candidate Key
- Super Key와 동일한 성격을 가지고 있는 Key
- 데이터를 식별해주나 최소한의 Column을 사용해야 한다. (Minimal Super Key)
- Primary Key도 Candidate Key 에서 뽑힌다.
# Example Of Super Key and Candidate Key
# 전화번호에 중복이 없다는 전제
| Id | Number | Name |
|----|---------------|----------|
| 1 | 111-1111-1111 | Seungmin |
| 2 | 222-2222-2222 | Jamie |
| 3 | 333-3333-3333 | LeeLee |
# Super Key
{Id}
{Number}
{Id, Number}
{Id, Name}
{Id, Number, Name}
{Number, Name}
# Candidate Key
{Id}
{Number}
- Alternate Key
- Primary Key로 선정되지 않은 Key들
- Primary Key로 선정되지 않은 Key들
- Compound Key 와 Composite Key
- 여러개의 Column을 묶어서 테이블에서 고유하게 식별가능하게 만든 복합키
- Compound Key는 Column 중에 Foreign Key 를 가질 수 있다.
- Composite Key는 Column 중에 Foreign Key 를 가질 수 도 있고 가지고 있지 않을 수 도 있다.
- Compound Key와 Composite Key를 구별하는 게 특별이 중요하지 않아서 자주 바꿔서 부른다고 한다.
- Surrogate Key
- 각 데이터들을 고유하게 식별하기 위한 대리로 만들어진 키
- 데이터 자체에는 아무런 의미도 없고, 정보도 없다.
- Primary Key 로 자주 사용되는 Auto increment 가 걸린 Id가 여기에 해당된다.
- Id 자체에는 아무런 뜻이 없으나 서비스 에서는 유저들을 식별하는 정보로 사용된다.
- Natural Key라고 반대 개념이 있는데 이것은 정보 자체를 사용해서 데이터들을 식별한다. 예를 들어 유저를 식별하는 값으로 주민등록번호 사용.
- Surrogate Key와 Natural Key 사이에서 Primary Key 를 고르는 문제가 빈번히 대두되는데 아무리 고유한 값이라도 일말의 바뀔 여지가 있는 Natural Key 보다는 (주민등록 번호 변경 등) 비즈니스 안에서는 절대 변할 수 없는 Surrogate Key 를 Primary Key 로 등록하는게 좋다.
DBMS의 키와 Mysql에서 사용하는 키의 차이점은 DBMS에서 말하는 Key들은 Concept에 가깝다. Mysql은 실제로 Primary Key와 Foreign Key 기능을 사용할 수 있고 나머지 Key들은 데이터베이스를 설계할 때 고려가 되는 개념들이었다.
MySql
- Key
- Key를 만들면 Index가 만들어진다.
- 결국 일반 Key는 Index와 동일하다.
- Primary Key
- Unique Key
- Foreign Key
Mysql Collation
Charset: 글자들을 어느정도 되는 크기에 집어 넣을 것인지 Collation: 텍스트들을 어떻게 정렬할 것인지
Mysql에서 지원하는 Collation
SHOW COLLATION
# 제일 자주 사용하는 charset인 utf를 지원하는 Collation
SHOW COLLATIOn
WHERE CHARSET LIKE ('%utf8%')

utf8과 utf8mb4의 Charset으로만 이루어진 Collation도 67개나 지원을 하고 있다. Mysql에서는 총 322개의 Collation을 지원하고 있다.
utf charset
한글을 사용하려면 utf8을 사용하면 된다. 웹에서는 자연스럽게 utf8로만 설정을 하면 되지만, mysql에서는 utf8, utf8mb4, utf16, utf32 로 다양한 utf를 지원한다. 나는 charset 크기가 점점 커져서 utf8 → utf8mb4 → utf16 → utf32 이런 순서로 만들어진 줄 알았는데 아니었다. 그리고 사용하는 공간이 큰 utf16과 utf32보다는 utf8과 utf8mb4가 많이 쓰인다.
utf8에서 utf8mb4가 생겨난 이유는 이모지들을 저장하기 위해서다. 원래대로라면 utf8은 8bits, 즉 1byte만 들어갈 것 같지만 사실 utf8은 1~4byte 까지 사용할 수 있는 가변크기를 가지고 있다. 그래서 plain text인 영어와 한국어는 각각 1byte, 3byte 크기를 이용해서 저장이 된다.
Mysql을 설계할때도 utf8형이 3byte를 넘어갈 일이 없다고 생각을 했어서인지 utf8이 실제로 저장할 수 있는 공간을 3byte로 제한을 해버렸다. 그런데 한자나 이모지들은 길이가 4byte인 문자열들이라서 Mysql에서 utf8을 쓰다가는 데이터가 다 들어가지를 않는다.
그래서 원래의 utf8의 취지에 맞게 1에서 4byte 까지 가변적으로 크기를 가질 수 있는 charset인 utf8mb4를 만들었다. 그리고 대부분의 경우 utf8mb4 Charset을 사용한다.
자주 사용하는 Collation
실제 서비스에서는 텍스트를 관리하는 Column은 대부분 utf8mb4_unicode_ci를 사용하고, 옛날에 실수로 잘못 설정을 했을 때 utf8mb4_general_ci를 사용했다. 여기서 ci란 Case Insensitive 의 약자로 대소문자를 구별하지 않겠다는 뜻이다.
# use case insensitive charset
SELECT *
FROM users
WHERE name = 'Jamie';
SELECT *
FROM users
WHERE name = 'jamie';
# 대소문자를 구별하지 않기 때문에 SELECT의 결과는 동일하다.
utf8mb4_bin
- bin은 binary의 약자이다.
- 바이너리 값을 그대로 저장한다.
-
utf8mb4를 사용하지만 텍스트가 아닌 바이너리값이 중심이라 파일이나 이미지를 저장하는 Column에 사용하면 된다.
utf8mb4_general_ci - 텍스트 형태로 정렬을 해준다.
- 한국어, 영어, 중국어, 일본어는 general_ci와 unicode_ci collation의 결과값이 동일하다.
- general_ci는 속도개선을 중점으로 하고 있기 때문에 정렬과 비교를 할 때 공식적인 Unicode 규칙을 따르지 않고 내부에서 따로 디자인을 했다.
- 그래서 때에 따라서 우리가 기대하는 (Unicode 규칙에 따른) 값이 나오지 않을 수 있다.
-
요즘은 CPU의 성능이 많이 좋아져서 Unicode 규칙을 따르지 않는 general_ci를 써가면서 성능향상을 할 필요가 없다!
utf8mb4_unicode_ci - Unicode 규칙을 따라서 정렬이 되었고 언어들 사이에서 제일 많이 선택받는 Collation.
- 특별한 기호들을 사용할때도 unicode_ci를 사용하는 편이라고 한다.
Reference
[Difference Between Key and Constraint]
[Difference Between Composite and Compound Key]
[Primary Key - Surrogate Key VS Natural Key]
Subscribe via RSS
{kind=link}