
[Java] Modern Java In Action
by Jamie Lee
Chapter 1
wkqk 8, 9, 10, 11 무슨 일이 일어나고 있는가?
지금까지의 대부분의 자바 프로그램은 코어 중 하나만을 사용했다. 자바 8이 등장하기 이전에는 나머지 코어를 활용하려면 스레드를 사용하는 것이 좋다고 조언했으나 스레드를 사용하면 관리하기 어렵고 많은 문제가 발생할 수 있다. 자바는 이러한 병렬 실행 환경을 쉽게 관리하고 에러가 덜 발생하는 방향으로 진화하려고 노력했다. 자바 9에서는 리액티브 프로그래밍이라는 병렬 실행 기법을 지원한다.
자바 8은 간결한 코드, 멀티고어 프로세서의 쉬운 활용이라는 두 가지 요구사항을 기반으로 한다.
자바 8은 데이터베이스 질의 언어에서 표현식을 처리하는 것처럼 병렬 연산을 지원하는 스트림이라는 새로운 API를 제공한다. (SQL은 SELECT, UPDATE 이런식으로 작성을 하면 내부에서는 C로 기대되는 명령을 처리한다). 즉, 스트림을 이용하면 에러를 자주 일으키며 멀티코어 CPU를 이용하는 것보다 비용이 훨씬 비싼 키워드 synchronized 를 사용하지 않아도 된다.
자바 8의 핵심 기능
- 스트림 API
- 코드를 전달하는 간결 기법 AKA 동작 파라미터화
- 인터페이스의 디폴트 메서드
메서드에 코드를 전달하는 기법을 이용하면 새롭고 간결한 방법으로 동작 파라미터화를 구현할 수 있고, 예전이라면 익명클래스를 이용해서 동작이 담긴 코드를 넘겼다. 또한 자바 8은 객체지향과 정반대의 개념에 있는 함수형 프로그래밍에서 위력을 발휘한다. 코드를 전달하고, 조합을 하는 등의 특성은 함수형프로그래밍이다.
왜 아직도 자바는 변하는가?
언어는 필요성에 따라서 만들어지고 도태된다. C와 C++은 프로그래밍 안전성이 부족해 바이러스가 침투하기 쉬우나 런타임 풋프린트가 적어서 다영한 임베디드 시스템에서 인기를 끌고 있다.
자바는 시작부터 스레드와 락을 이용한 동시성을 지원하고, 유용한 라이브러리도 많이 가지고 있었다. 코드를 JVM 바이트 코드로 컴파일 하는 특징 때문에 (모든 브라우저는 가상머신 코드를 지원) 인터넷 애플릿 프로그램의 주요 언어가 되었다.
프로그램 생태계는 빅테이터라는 도전에 직면하면서 멀티코어 컴퓨터나 컴퓨팅 클러스터를 이용해 빅데이터를 효과적으로 처리할 필요성이 커졌다. 즉, 병렬 프로세싱을 이용해야 했고, 이는 자바에 부족한 기술이었다.
새로운 하드웨어, 새로운 프로그래밍이 등장하는 것처럼 기후가 변하고 식물에 영향을 미치면서 기존 식물을 대신해서 새로운 식물을 길러햐 하는 것처럼 새로운 프로젝트에는 다른 언어를 선택해야 하고, 자바는 또 선택을 받기 위해 노력해야 한다.
자바 8의 밑바탕이 된 설계
스트림 처리
스트림이란 한 번에 한 개씩 만들어지는 연속적인 데이터 항목들의 모임이다. 이론적인 프로그램은 입력 스트림에서 데이터를 한 개 읽어들이며 마찬가지로 출력 스트림으로 데이터를 한 개씩 기록한다. 우선은 스트림 API가 공장의 조립 라인처럼 어떤 항목을 연속으로 제공하는 어떤 기능이라고 단순하게 생각하자.
cat file1 file2 | tr "[A-Z]" "[a-z]" | sort | tail -3
유닉스가 명령을 스트림으로 처리하는 대표적인 예시이다. 스트림으로 처리하기 때문에 cat과 tr 등의 앞의 명령어가 파일을 끝까지 처리하고 있지 않아도 sort나 tail 이 작동할 수 있다.
자바 또한 유닉스가 복잡한 파이프라인을 만드는 것처럼 많은 메서드를 지원하는데 중요한 건 딱 하나다! 우리가 원하는 쿼리를 실행하기 위해 SQL문을 돌리고 밑에서는 C로 어떤 일이 일어나는지 전혀 모르는 것처럼, 우리가 스트림 API를 쓴다면 밑에서는 무슨 일이 일어나는지 전혀 모르면서 스트림 형태의 기능을 쓸 수 있다. 또한 스트림의 가장 큰 장점은 우리가 조금의 변경사항을 준다면 작업을 여러 CPU 코어에 쉽게 할당해서 병렬성을 얻으면서도 스레드라는 복잡한 작업을 하지 않아도 된다.
동작 파라미터화로 메서드에 코드 전달하기
이전에도 익명 클래스로 코드를 전달할 수는 있었으나 너무 복잡했다. 코드를 넘긴다는 개념이 잘 안 와닿는다면 이렇게 sorting해주세요~ 하고 컨디션 값 하나만 넘기는게 아니라 아예 sorting을 해주는 코드 자체를 (약간 too much 하지만) 넘겨준다고 생각하면 된다!
// 대표적인 익명 클래스 형식
Collections.sort(inventory, new Comparator<Apple>() {
public int compare(Apple al, Appple a2) {
return al.getWeight().compareTo(a2.getWeight());
}
});
병렬성과 공유 가변 데이터
스트림 메서드로 전달하는 코드는 다른 코드와 동시에 실행하더라도 안전하게 실행될 수 있어야 한다. 다른 코드와 동시에 실행 하더라도 안전하게 실행할 수 있는 코드를 만들려면 공유된 가변 데이터에 접근하지 않아야 한다. 두 프로세스가 공유된 변수를 동시에 바꾸려하면 어떻게 될지 생각해보라.
기존처럼 어렵게 synchronized를 이용해서 공유된 가변 데이터를 보호하는 규칙을 만들 수 는 있지만 자바 스트림 API는 자바 스레드 API보다 설정 몇개로 더 쉽게 병렬성을 활용할 수 있다.
동작 파라미터화 코드 전달하기
그냥 chapter2에서는 동작 파라미터화 aka 함수 전달하기가 어떤 과정으로 진화가 되어왔나를 보여주고 있다. 함수 자체를 넘기는 이유는 이게 더 자잘하게 플래그 넘기는 것 보다 확장성이 있기 때문. 어쨌든 중요한 점은 시시각각 변하는 사용자 요구 사항에 비용이 가장 최소화 될 수 있는 것!
발전단계: 플래그로 동작 분기 (최악) → 함수형 인터페이스 → 익명 클래스 → 람다
동작 파라미터화란 아직은 어떻게 실행할 것인지 결정하지 않은 코드 블록을 의미한다. 이 코드 블록은 나중에 프로그램에서 호출한다. (람다로 넘겨주게 된다)
1) 어떻게 필터링을 할 지 플래그를 추가해서 결정
List<Apple> filterApples(List<Apple> apples, Color color, int weight, boolean flag) {
List<Apple> result = new ArrayList<>();
for(Apple apple : apples) {
if((flag && apple.getColor().equals(color)) ||
(!flag && apple.getWeight() > weight)) {
result.add(apple);
}
}
return result;
}
실전에서는 이런 방법을 쓰면 안된다. 1) true와 flase가 뭘 의미하는지도 모르겠고 2)앞으로 필터링 요구 사항이 추가되면 확장을 하기도 정말 힘들다. 이렇게 얄팍하게 변수 하나로 분기를 하고 동작을 달리 하는 것보다 기본 동작은 똑같고 메인이 되는 (여기서는 필터링 조건 등등) 동작 자체를 다르게 하면 어떨까? → 동작 파라메터화
2) 함수형 인터페이스를 이용
요구 상황에 따라 출력을 해야 하는 정보가 다른 메서드가 있다. 아까와는 달리 값을 이해하기 어려운 플래그로 동작을 분기하지 않고 함수형 인터페이스를 넘겨줘서 동작을 달리해보았다.
interface PrintPredicate {
String print(Apple apple);
}
class PrintWeightPredicate implements PrintPredicate {
@Override
public String print(Apple apple) {
return Integer.toString(apple.getWeight());
}
}
class PrintHeavyLightPredicate implements PrintPredicate {
int middleWeight = 20;
static final String APPLE_HEAVY = "heavy";
static final String APPLE_LIGHT = "light";
@Override
public String print(Apple apple) {
if(apple.getWeight() > middleWeight) {
return APPLE_HEAVY;
}
return APPLE_LIGHT;
}
}
public class Quiz2Dash1 {
public static void prettyPrintApple(List<Apple> inventory, PrintPredicate p) {
for(Apple apple : inventory) {
String output = p.print(apple);
System.out.println(output);
}
}
public static void main(String[] args) {
Apple one = new Apple(Color.GREEN, 100);
Apple two = new Apple(Color.RED, 20);
Apple three = new Apple(Color.RED, 10);
List<Apple> apples = Arrays.asList(one, two, three);
prettyPrintApple(apples, new PrintHeavyLightPredicate());
prettyPrintApple(apples, new PrintWeightPredicate());
String test = "test";
}
}
- 일단 오직 하나의 추상 메서드만 있는 인터페이스(함수형 인터페이스)를 선언한다
- 각자 요구 사항에 맞춰 인터페이스를 구현한 클래스들을 만든다
- 이 인터페이스를 파라메터로 (동작 파라메터) 받는 메서드를 만든다
- 실제로 실행 단에서 이 메소드를 호출하며 동시에 동작을 담고 있는 클래스를 던져준다.
대표적인 함수형 인터페이스로는 정렬을 하는 Comparator의 sort, 쓰레드를 이용해서 코드 블록을 실행하는 Runnable의 run, 메소드를 호출하는 Callable의 call이 있다.
이런 형태를 전략 디자인 패턴 Strategy design pattern 이라고 한다.
전략 디자인 패턴은 각 알고리즘을 캡슐화하는 알고리즘 패밀리(구현)들을 정의해둔 다음에 런타임에 알고리즘을 선택하는 기법이다. 예제에서는 컬렉션 탐색 로직과 적용할 동작을 분리했다! 이렇게 하면 한 메서드가 다른 동작을 수행하도록 재활용을 할 수 있다. → 캡슐화
3) 익명 클래스를 이용
아무래도 위의 방법은 인터페이스를 만들고 구현하는 등 자질구레한 일들이 굉장히 많아서 귀찮다! 이를 조금이라도 줄이고자 자바는 클래스 선언과 인스턴스화를 동시에 수행하는 익명 클래스를 만들었다.
// 익명 클래스로 만들어보기
prettyPrintApple(apples, new PrintPredicate() {
@Override
public String print(Apple apple) {
return Integer.toString(apple.getWeight());
}
});
prettyPrintApple(apples, new PrintPredicate() {
int middleWeight = 20;
static final String APPLE_HEAVY = "heavy";
static final String APPLE_LIGHT = "light";
@Override
public String print(Apple apple) {
if(apple.getWeight() > middleWeight) {
return APPLE_HEAVY;
}
return APPLE_LIGHT;
}
});
이렇게 하면 클래스들을 만들고 인스턴스로 만든 다음에 쓰는 과정을 확 줄일 수는 있는데 이렇게 해버리면 딱 한 번 쓰고 또 쓰려면 익명 클래스로 또 만들어줘야 해서 만약 반복 사용을 한다고 하면 좋은 방법은 아닌 것 같다. 그리고 익명 클래스의 형태가 익숙하지 않은 사람들도 많다.
익명클래스는 자바의 local class와 비슷한 개념이다. 이름이 없는 클래스로, 이를 이용하면 클래스 선언과 인스턴스화를 동시에 할 수 있고 즉석에서 필요한 구현을 만들어 사용할 수 있다.
4) 람다 표현식 이용
// 람다로 던져보기
prettyPrintApple(apples, (Apple apple) ->
Integer.toString(apple.getWeight())
);
prettyPrintApple(apples, (Apple apple) -> {
int middleWeight = 20;
String APPLE_HEAVY = "heavy";
String APPLE_LIGHT = "light";
if(apple.getWeight() > middleWeight) {
return APPLE_HEAVY;
}
return APPLE_LIGHT;
});
내가 만든 예제는 람다를 던져도 극단적으로 간단해 보이지는 않는데 람다를 사용하면 명시적으로 클래스를 안 만들어도 되기 때문에 훨씬 더 간단한 형태로 보인다.
코드 전달 기법을 이용하면 동작을 메서드의 인수로 전달할 수 있다. 자바 8이전에는 이런 작업을 하고 싶다면 상당수의 코드가 추가되었다. 익명 클래스가 있다고 해도 인터페이스를 상속받아 여러 클래스를 구현해야 하는 수고는 여전했는데 람다로 이걸 해결했다.
Chapter 3 람다 표현식
람다를 쓰는 이유? 익명 클래스로 다양한 동작을 구현할 수 있지만 만족할 만큼 코드가 깔끔하지 않아서.
아무튼 중요한 사실은 익명클래스도 람다도 코드를 인수로 전달 할 수 있는 귀중한 기능이다. 더 정확하게는 람다 표현식은 메서드로 전달할 수 있는 익명 함수를 단순화한 것이라고 할 수 있다. 람다 표현식에는 이름이 없지만, 파라미터 리스트, 바디, 반환 형식, 발생할 수 있는 예외 리스트는 가질 수 있다.
익명: 이름이 없어서 익명이다. 메서드를 안 만드니 작명 걱정도 안하고 구현할 코드에 대해 걱정이 줄어든다.
함수: 람다는 메서드처럼 특정 클래스에 종속이 안되어서 그냥 함수라고 부른다.
전달: 람다는 코드를 인수로 전달하는 귀중안 기능
간결성: 익명 클래스보다 훨씬 보기 쉽고 깔끔, 자질구레한 것이 많이 줄었다.
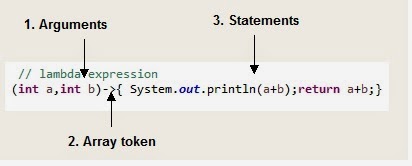
람다의 구조인데 앞 부분은 파라메터의 리스트, → 모양은 람다의 파라미터 리스트와 바디를 구분하는 용도이고, 그 뒤가 람다의 바디이다. 람다의 바디를 {}로 쌓기도 하는데 나중가면 저렇게 싼 형태가 더 알아보기 힘들다고 한다…
람다 표현식에는 return이 함축되어있어서 웬만하면 return을 직접 명시하지 않는다.
(param) -> expression
(param) -> { statements; }
// expression 표현식
b + 1
// statements 구문
a = b + 1;
// expression statement
a++;
// 무슨 차이가 있나 했더니 statement가 최종 값을 넣는 형태로
// 완성된 형태라서 expression을 포함하고 있다.
3.2 어디에, 어떻게 람다를 사용하나?
람다를 사용할 수 있는 부분은 함수형 인터페이스를 파라메터로 받는 자리이다. 함수형 인터페이스란 오직 하나의 추상메서드만 가지고 있는 인터페이스이다. 예시의 코드처럼 @FunctionalInterface 어노테이션이 함께 있다.
람다 표현식으로 함수형 인터페이스의 추상 메서드 구현을 직접 전달할 수 있으므로 전체 표현식을 함수형 인터페이스의 인스턴스로 취급한다. 따지고보면 함수형 인터페이스를 구현한 클래스의 인스턴스로 취급하는 것이다.
@FunctionalInterface
public interface Predicate<T> {
/**
* Evaluates this predicate on the given argument.
*
* @param t the input argument
* @return {@code true} if the input argument matches the predicate,
* otherwise {@code false}
*/
boolean test(T t);
람다가 이름도 없이 그냥 띡 던져놓기만 해도 관련 메소드를 착착 만들 수 있었던 이유는.. 함수형 메서드가 가지고 있는 메서드는 하나니까 어련히 저걸 만들어서 던지겠지 하는 것도 있고 람다가 던지는 파라메터 리스트, 반환 값을 맞춰본다.
3.3 람다 활용: 실행 어라운드 패턴
자원 처리(데이터 베이스, 파일 등등)에 사용하는 순환 패턴은 자원을 열고, 처리한 다음에 자원을 닫는 순서로 이루어진다. 이걸 실행 어라운드 패턴이라고 한다.
여기서 어떻게 람다를 활용하나? 어차피 실행부를 감쌓는 자원열고닫기 부분은 동일하다. 실행부에서 뭘 하는지가 중요한데 그 실행부를 동작 파라메터화를 시키고, 실제로 호출을 할 때 내 입맛에 맞게 람다로 만든 표현식을 던지면 일이 간단해진다.
- 함수형 인터페이스 만들기
- 함수형 인터페이스를 파라메터로 받는 재활용 메서드 만들기
- 재활용 메서드 안에서 함수형 인터페이스의 단 하나 뿐인 추상메서드 호출하기
- 실제 실행 단에서 재활용 메서드 호출 할 때 원하는 행동 람다로 만들어서 던지기
@FunctionalInterface
interface FileProcess {
void work (BufferedReader b);
}
public class ExFile {
static void processFile(FileProcess p) {
// try-with-resource 형태라서 따로 자원을 닫을 필요가 없어졌다!
try (BufferedReader reader = new BufferedReader(new FileReader("C:\\Temp\\file1.txt"))) {
p.work(reader);
} catch (Exception e){
System.out.println(e.getMessage());
}
}
public static void main(String[] args) {
// 1그냥 파일 읽기
processFile((BufferedReader r) -> {
try {
System.out.println(r.readLine());
} catch (IOException e) {
e.printStackTrace();
}
});
// 2 파일 내용 복사하기
processFile((BufferedReader r ) -> {
try {
try (BufferedWriter r2 = new BufferedWriter(new FileWriter("C:\\Temp\\file2.txt"))) {
r2.write(r.readLine());
}
} catch (IOException e) {
e.printStackTrace();
}
});
}
}
책에서 말한 것처럼 실행어라운드는 동일하게 사용하고 자원을 실제로 어떻게 사용할 것인지는 람다로 전달해 내 마음대로 실행을 했다. try-with-resource 형식을 잘 기억하자. 이걸 그대로 사용하면 매번 따로 자원을 닫아주는 번거로운 일을 하지 않아도 된다. 그냥 자원을 열 때 try () 안에서 연다는 걸 알면 된다.
3.4 함수형 인터페이스 사용
함수형 인터페이스의 추상 메서드는 람다 표현식의 시그니처 (반환값, 파라메터값)을 묘사한다. 함수형 인터페이스의 추상 메서드 시그니처를 함수 디스크립터라고 한다.
앞에서도 말한 것처럼 람다는 함수형 인터페이스에서 사용이 가능한데 자바는 이미 다양한 형태의 함수 인터페이스를 상황별로 만들어놨고 우리는 필요에 따라서 반환값과 파라메터값을 고려해서 쓰기만 하면 된다. (Comparable, Runnable, Callable 등등)

대략적인 쓰이는 상황들
Predicate: 객체를 사용해서 boolean 값 return, 한마디로 true/false 값 나누고 싶을 때 사용 (test)
public class ExPredicate {
// 맨 앞 <T> 왜 있나 했는데 filter 에서 쓰이는 T를 정의해주는 느낌이다
public static <T> List<T> filter(List<T> list, Predicate<T> p) {
List<T> results = new ArrayList<>();
for(T t: list) {
if(p.test(t)) {
results.add(t);
}
}
return results;
}
// 람다의 준비물
// 1.functional method
// 2.recycle method
// 3.call recycle method with lambda
public static void main(String[] args) {
List<String> sample = Arrays.asList("longlong", "short", "");
List<String> notShort = filter(sample, (String s) -> s.length() > 3);
System.out.println(notShort);
IntPredicate same = (int i) -> i == 1000;
Predicate<Integer> sameBoxing = (Integer i)-> i == (new Integer(1000));
System.out.println(same.test(1000));
System.out.println(sameBoxing.test(1000));
}
List<Apple> filterApples(List<Apple> apples, Color color, int weight, boolean flag) {
List<Apple> result = new ArrayList<>();
for(Apple apple : apples) {
if((flag && apple.getColor().equals(color)) ||
(!flag && apple.getWeight() > weight)) {
result.add(apple);
}
}
return result;
}
}
Consumer: 객체를 인수로 받아서 어떤 행동을 하고 싶을 때 (accept)
public class ExConsumer {
// Consumer 은 반환값이 없어서 뭔가를 실행하고자 할 때 사용한다
public static <T> void doSomething(List<T> list, Consumer<T> c) {
for(T t: list) {
c.accept(t);
}
}
public static void main(String[] args) {
List<Integer> test = Arrays.asList(1,2,3);
doSomething(test, (Integer i) -> System.out.println(i/2));
}
}
Function: 객체를 인수로 받아서 또 다른 타입의 객체를 반환한다, 가장 함수다운 함수 (apply)
public class ExFunction {
// Function 은 입력 값도 있고 반환 값도 있는 형식이다.
static <T, R> Map<T, R> map(List<T> list, Function<T, R> f) {
Map<T, R> valueMap = new HashMap<>();
for(T t:list) {
valueMap.put(t, f.apply(t));
}
return valueMap;
}
public static void main(String[] args) {
List<String> test = Arrays.asList("one", "two", "Three");
Map<String, Integer> testLen = map(test, String::length);
System.out.println(testLen);
}
}
기본형 특화 (IntPredicate, IntSupplier etc)
기본형 값들을 위의 메소드에 사용하려면 참조형만 값으로 받는 제네릭의 특성 때문에 Integer, Double등으로 박싱을 해야 한다. 최신 자바는 오토박싱을 해주기는 하는데 박싱은 객체라서 힙에 차곡차곡 쌓이게 된다. 결국 메모리를 더 쓰게 되고, 기본형을 가져올때도 메모리 탐색을 해야 한다.
이것이 모이면 결국 자원낭비라서 그냥 기본형으로 함수형인터페이스를 사용한다면 기본형 특화를 쓰는게 좋다.
자바에서 미리 만들어둔 함수형 인터페이스 말고도 우리가 원하는 함수형 인터페이스는 언제든 만들 수 있다.
3.5 형식 검사, 형식 추론, 제약
다이아몬드 연산자
람다 표현식으로 함수형 인터페이스의 인스턴스를 만드는 것은 일종의 추론이라고 할 수 있다. 함수형 인터페이스의 유일한 추상 메서드의 파라메터 값과 반환값 형태와 동일한 람다 형식을 쓰면 아~ 그건가보다~ 하고 납득을 하기 때문에.
그런데 이런 경우가 하나 더 있다. 바로 다이아몬드 연산자 이다.
List<String> listOfStrings = new ArrayList<>();
List<Integer> listOfIntegers = new ArrayList<>();
이렇게 다이아몬드 연산자를 사용해서 콘텍스트에 따라 제네릭 형식을 추론하고 있다.
3.5.3 형식추론
사실 이미 간단한 형태의 람다를 더 간단한 형태로 만들수 있다면? 람다 생성은 완전히 자바 컴파일러가 추론을 하는 형태로 이루어져있다. 결과적으로 컴파일러는 람다 표현식의 파라미터 형식에 접근을 할 수 있어서 람다 문법에서는 사실 파라미터를 생략해도 된다.
public static void main(String[] args) {
List<Integer> test = Arrays.asList(1,2,3);
doSomething(test, (Integer i) -> System.out.println(i/2));
}
// 파라미터 제거
public static void main(String[] args) {
List<Integer> test = Arrays.asList(1,2,3);
doSomething(test, (i) -> System.out.println(i/2));
}
두 개의 코드는 완전히 동일한 코드이다. 상황에 따라 명시적으로 형식을 포함하는 것이 좋을 때도 있고 형식을 배제하는 것이 가독성을 향상시킬 때고 있다. 어떤 방법을 해야 할지는 역시나 개발자 스스로가 직접 판단을 해야 한다.
3.5.4 지역 변수 사용
람다 표현식에서는 다른 메서드들과 마찬가지로 자유 변수(파라메터로 넘겨진 변수 말고 외부에서 선언이 된 변수)를 활용할 수 있다. → 람다 캡쳐링
그런데 이렇게 람다에서 외부에서 선언된 변수에 접근을 하려면 그 변수는 딱 한 번 만 값을 넣을 수 있는 final 변수여야 한다. 이름에서부터 알 수 있는 것처럼 ‘캡처링’이니까 값이 바뀌면 캡쳐의 개념이 아니게 되는 것. 아니면 Effective final 이라고 그냥 그 변수가 선언이 되고 딱 한 번만 할당이 되었으면 final이라고 명시를 안 해도 컴파일러가 알아서 final 처럼 취급을 해준다.
이런 제약이 있는 이유는 인스턴스 변수와 지역 변수가 태생부터 다르기 때문이다.
인스턴스 변: 힙에 저장이 된다. (조금 더 오래 살아남는 값들이 힙에 저장이 되는 편)
지역변수: 스택에 저장이 된다. (기본타입과, 참조타입들의 이름들이 여기에 저장이 되는 편)
특정 메소드에서 사용이 되는 변수가 지역변수이다. 얘들은 메소드가 호출이 되었을 때 스택에 값이 차곡차곡 쌓였다가 메소드 연산이 끝나면 순서대로 다 팝팝팝 해서 터진다.
Reference
[자바 메모리 관리 - 스택 & 힙]
[JVM의 메모리 구조 및 할당과정]
[Stack Memory and Heap Space in Java | Baeldung]
그리고 사실은! 람다에서 접근을 하는 외부 선언 변수는 람다가 그 외부 선언 변수 값 자체에 접근을 하는 게 아니고, 외부 선언 변수 값의 복사본에 접근을 하는 것이다. (call-by-value 형식이라고 할 수 있음). 그래서 그 복사본의 값이 바뀌지 않아야 해서 값을 한 번 만 할당하게 하는 것.
애초에 이런 형식으로 된 이유는 스레드 세이프하게 만들기 위해서. 람다가 스레드(1)에서 실행된다면 변수를 할당한 다른 스레드(2)가 사라져버려 변수 할당이 해제 되었는데도 람다에서는 계속 그 변수에 접근을 하려고 할 수 있다.
따라서, 람다는 자신이 정의된 메서드의 지역 변수의 값은 바꿀 수 없다. 람다가 정의된 메서드의 지역 변수닶은 final 변수기 때문에. → 람다는 변수가 아닌 값에 국한되어 어떤 동작들을 수행한다.
그리고 지역변수 값은 스택에 존재하기 때문에 자신을 정의한 스레드와 생존을 같이 해야 한다.
3.6 메서드 참조
메서드 참조를 이용하면 기존의 메서드 정의를 재활용해서 람다처럼 전달을 할 수 있다. (동작 파라메터). 때때로 람다 표현식을 쓰는 것보다 메서드 참조를 사용하는 게 더 가독성이 좋고 자연스러울 수 있다. 왜냐하면 메서드 참조는 어떤클래스.어떤메소드 형태로 넘기기 때문에 확실히 명시된다는 느낌이 있다.
static List<Apple> filterApples(List<Apple> inventory, Predicate<Apple> p) {
List<Apple> result = new ArrayList<>();
for(Apple apple: inventory) {
if(p.test(apple)) {
result.add(apple);
}
}
return result;
}
List<Apple> result1 = filterApples(apples, Apple::isHeavyApple);
List<Apple> result2 = filterApples(apples, Apple::isGreenApple);
어떤 메소드를 실행해야 하는지 대놓고 이름을 가져와서 보여주고 있다. 훨씬 더 명시된 모습. 그런데 실제로 메서드를 호출하는 건 아니고 람다에서 이렇게이렇게 동작을 하세요! 하고 코드를 짜서 넘겨주는 것처럼 실제로 실행을 할 때 이 메서드를 호출하세요~ 의 뜻이라서 메서드 참조를 할 때 메서드 뒤에 ()을 쓰지 않아도 된다.
메서드 참조 유형
- 정적 메서드 참조 Integer::parseInt (parseInt는 static 메서드)
- 인스턴스 메서드 참조 String::length (length는 일반 메서드)
- 기존 객체의 인스턴스 메서드 참조
String test = new String("hello");
someMethod(test::length);
3번의 형태를 쓰는 경우는 람다 외부에서 (final로) 생성이 된 변수들의 메서드를 람다 안에서 사용을 할 때 쓰는 형태라고 한다. 이런식은 비공개 본 클래스 전용 핼퍼 메서드를 정의한 상황에서 유용하게 쓸 수 있다고 한다.
컴파일러는 람다 표현식의 형식을 검사하던 방식과 비슷한 과정으로 메서드 참조가 주어진 함수형 인터페이스와 호환하는지 확인한다. 메서드 참조는 콘텍스트의 형식과 일치해야 한다.
Supplier<Apple> c1 = Apple:new;
Apple a1 = c1.get();
위 방식처럼 생성자 참조도 사용을 할 수 있는데 아직은 어떻게 사용을 해야 하는지 느낌이 잘 오지 않는다. 대신에 Map으로 카테고리별로 생성자 참조를 해놔서 값 맵핑해서 객체 만드는 건 좋아보인다. 근데 생성자로 객체를 만들었다고 해도 기본 생성자로 객체를 만들고, 값을 넣어주는 것은 다 따로 해야 하지 않을까 들어가는 인수들이 다르니까. 그리고 값 세팅은 Function이나 BiFunction으로 하는데 이러면 많아봐야 값 두 개 까지만 넣어서 생성을 할 수 있다.
3.8 람다 표현식을 조합할 수 있는 유용한 메서드
여러가지 유틸성 함수형 메서드들을 조합해서 사용을 할 수 있다. 한 마다로 간단한 여러개의 람다 표현식을 조합해서 복잡한 람다 표현식을 만들 수 있다.
함수형 인터페이스가 이렇게 만능으로 구현이 될 수 있는 이유는 default메서드로 발라져있기 때문이다. 미래를 생각해서 이것저것 다 넣어놓고 구현 안 해도 되는 default를 추가한 것 같다.
심지어 이렇게 람다 표현식을 복잡하게 조합을 해도 코드 자체가 문제를 잘 설명한다고 한다.
이는 결국 내가 함수형 메서드를 만들었을 때도 미래지향적으로 핼퍼 메서드를 이거저거 만들어 놓으면 연결연결연결 해서 쓸 수 있다는 얘기다.
Comperator 연결
// 역정렬
inventory,sort(comparing(Apple:getWeight).reversed());
/**
* Returns a comparator that imposes the reverse ordering of this
* comparator.
*
* @return a comparator that imposes the reverse ordering of this
* comparator.
* @since 1.8
*/
default Comparator<T> reversed() {
return Collections.reverseOrder(this);
}
// 값이 같다면 다른 조건 하나 더 넣어서 비교
inventory.sort(comparing(Apple:getWeight).reversed()
.thenComparing(Apple:getCountry));
default Comparator<T> thenComparing(Comparator<? super T> other) {
Objects.requireNonNull(other);
return (Comparator<T> & Serializable) (c1, c2) -> {
int res = compare(c1, c2);
return (res != 0) ? res : other.compare(c1, c2);
};
}
Predicate 연결
// and 조건
Predicate<Apple> redAntHeavyApple = redApple.and(apple -> apple.getWeight() >150);
// or 조건
Predicate<Apple> redAndHeavyAppleOrGreen = readApple.and(apple -> apple.getWeight() > 150)
.or(apple -> GREEN.equals(a.getColor()));
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
Function 연결
// andThen 주어진 함수를 먼저 적용한 결과를 다른 함수의 입력으로 전달
Function<Integer, Integer> f = x -> x + 1;
Function<Integer, Integer> g = x -> x * 2;
Function<Integer, Integer> h = f.andThen(g);
int result = h.apply(1); //4가 나온다.
// compose 인수로 주어진 함수를 먼저 실행한 다름에 결과를 외부 함수로 전달
Function<Integer, Integer> f = x -> x + 1;
Function<Integer, Integer> g = x -> x * 2;
Function<Integer, Integer> h = f.compose(g);
int result = h.apply(1); //3가 나온다.
// 결국 andThen과 compose 의 차이는 앞을 먼저 계산하냐 뒤를 먼저 계산하냐의 차이
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
*이렇게 람다로 호출을 바로 못하고 함수형 메서드로 여러개를 만들어서 체인을 걸어야 하는 이유는 저 메서드들이 함수형 메서드에 들어있는 애들이다 보니까 확실하게 함수형 메서드로 객체 선언이 되어야 한다. 저렇게 만들어놓으면 람다로 던지지 않고 그냥 redAndHeavyApple 이렇게 자체를 던져서 사용을 하면 되겠다.
실제 호출 모습
Predicate<Apple> redApple = apple -> apple.getColor().equals(Color.RED);
Predicate<Apple> redAntHeavyApple = redApple.and(apple -> apple.getWeight() >150);
List<Apple> finalResult = filterApples(apples, redAntHeavyApple);
System.out.println(finalResult);
Subscribe via RSS
{kind=link}